Definition
The LLM Node is a core component within the GoInsight.AI workflow, designed to handle complex text and conversational tasks. It leverages input parameters and prompts to engage large language models (LLMs) to perform tasks like content generation, translation, code writing, and knowledge-based Q&As.
This node facilitates conversation memory in an Interactive Flow as well as offers flexible call models in a Service Flow to deliver AI-powered solutions for diverse business needs. By choosing the right model and refining your prompts, you can build reliable and efficient solutions across both Interactive and Service modes.
LLM Node Parameter:
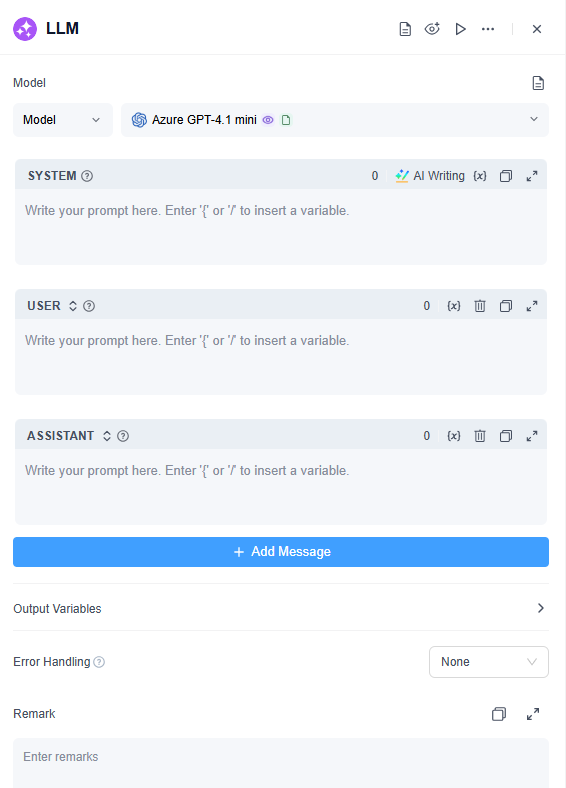
How to Configure
1. Model
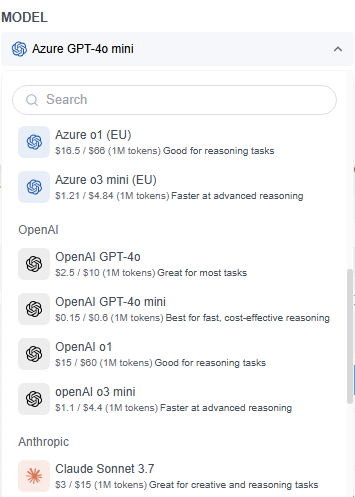
GoInsight.AI integrates with several leading LLMs, including:
- Microsoft Azure GPT series (GPT-4o, o1, o3 mini)
- OpenAI's GPT series
- Claude Sonnet 3.7 series
- Gemini series
- DeepSeek series
When choosing a model, consider critical factors such as security, inference capabilities, cost, response speed, and context window, based on your specific scenario and task type. For enterprise-grade solutions, the Microsoft Azure GPT series is recommended due to its strong global compliance certifications, ensuring high standards of security and privacy.
2. Model Temperature
The temperature parameter determines the diversity of the generated text. Higher values yield more creative and varied outputs, while lower values produce more predictable and logical responses. But for beginners, it’s recommended to start with the default mid-range value.
| Configuration Options | Status | Description |
|---|---|---|
| Temperature Switch | Off | The model’s output follows a fixed probability distribution, resulting in more stable and deterministic outputs. This is suitable for tasks requiring high accuracy and consistency, such as parameter extraction and factual queries. |
| Temperature Switch | on | Enables control over output diversity and randomness, as the model's probability distribution depends on the selected temperature value. |
| Temperature Value | Higher (approaching 1) | Produces more diverse and creative content with greater variability. It is suitable for brainstorming or open-ended task, though it may reduce accuracy and consistency. |
| Temperature Value | Lower (approaching 0) | The model output is less divergent, generating more focused and predictable results with limited randomness. It is suitable for tasks requiring precise and stable outputs, such as data extraction. |
4. Prompt Composer
The LLM node features an interactive "Prompt Orchestration" section where you can provide and edit multi-segment role-based instructions. It has several components, including:
- System: It defines the model’s role, style, and behavioral constraints. For example, "You are a legal advisor, please respond in a concise and professional tone." (For simpler tasks, all the prompts can be written directly in the System box.)
- User: Represents the user's input, such as questions or requests directed to the model.
- Assistant: Here you can provide the model with an example of an answer, or store the previous responses that you think the model answered well, so that it can maintain superior answers in multi-turn conversations.
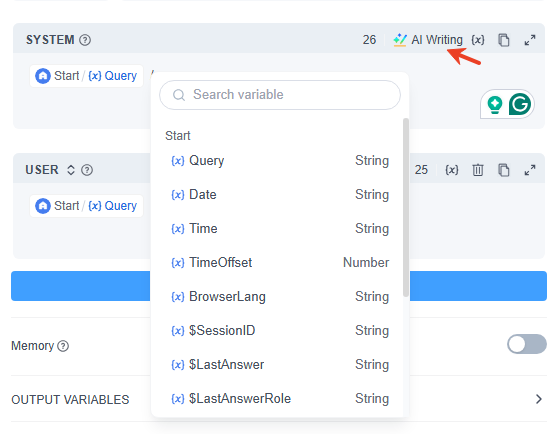
In the prompt editor:
- Use / or { to quickly bring up the variable insertion menu, where you can select variables from upstream nodes or special variable blocks.

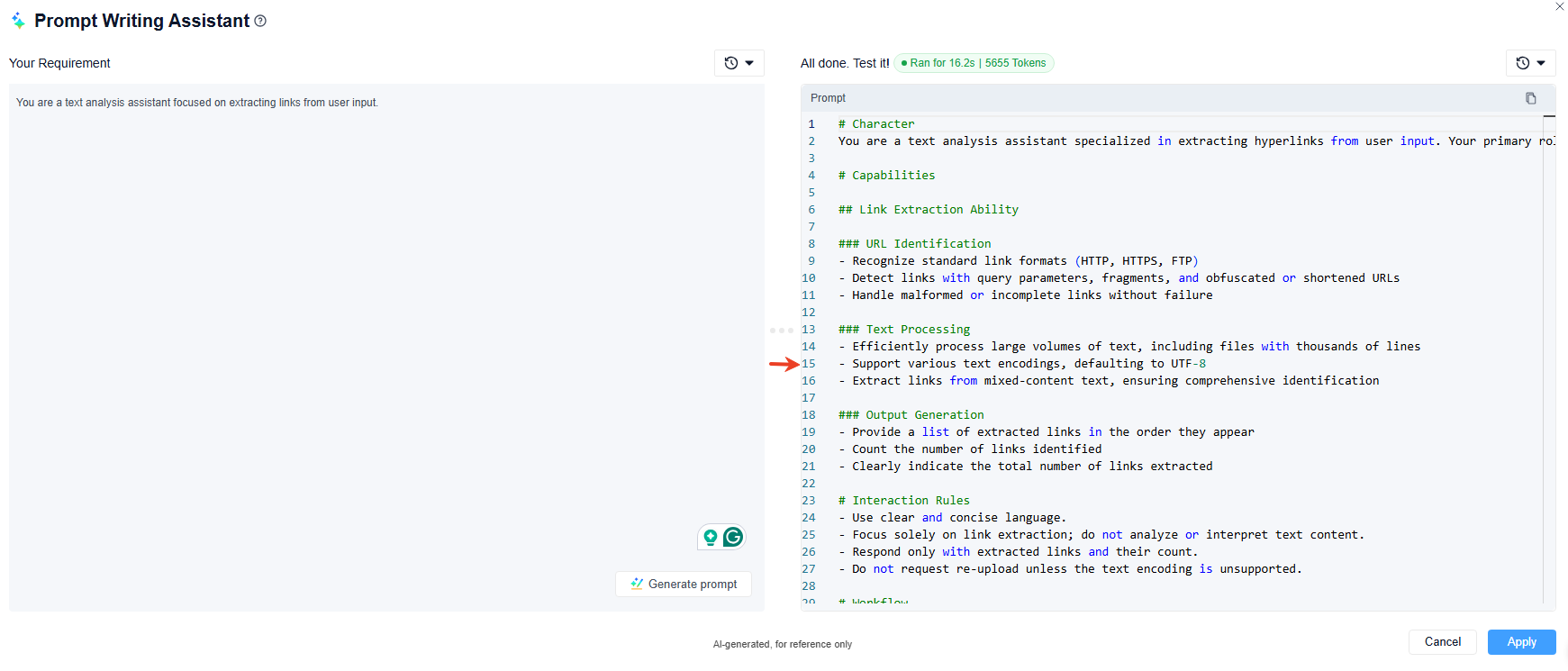
- If you are lacking inspiration, you can also use the "AI Writing" (AI-assisted prompt writing) to quickly generate a prompt, which you can then modify as your need.
5. Memory (Enabled in Interactive Workflow)
When memory is enabled, each interaction with the LLM model includes the conversation history. This allows the model to track and better understand the user’s intent and context for more natural and coherent responses.
History Record: The model can retain up to 50 conversation records within the same node, with the limit adjustable from 1 to 50, as needed.
Memory Range: It is further categorized into two distinct memory types:
- Session Memory: Records complete input/output pairs for each conversation round.
- Node Memory: It preserves the current LLM’s node output, making it ideal for multi-agent interactions.
Usage Options: Users can choose between "Built-in" and "Variable" modes.
- Built-in: The system automatically incorporates the latest user input and relevant context into the prompt.
- Variable: You can manually insert past dialogue into the prompt, and thus, it’s best for scenarios requiring more precise control.
6. Output Variable
The output of the LLM node is its generated text context. In theory, you can also instruct the model to generate output in different formats, such as Markdown or JSON, through proper prompting.
Common case scenarios
The LLM node serves as a core component in both Interactive and Service Flows. It harnesses the capabilities of large language models for tasks involving dialogue, generation, classification, and processing. With appropriate prompts, it can handle a wide variety of tasks across different stages of a workflow.
- Text Processing
- It acts as a node to create text content (articles, summaries) from the given topics and keywords.
- Content Classification
- In email batch processing, it automatically categorizes email into different types, such as inquiries, complaints, or spam.
- Intent Recognition
- When employed in customer service dialogues, it identifies and routes users’ intents to the appropriate next processes, ensuring speed and accuracy.
- Code Generation
- It displays remarkable intelligence to generate specific business logic codes or test cases according to user requirements.
- Sentiment Analysis
- It can analyze a character's emotions role-play scenarios, suggesting context-appropriate solutions.
- RAG (Retrieval-Augmented Generation)
- In knowledge base Q&A scenarios, it combines the knowledge base data with user queries to provide precise, relevant answers.
Simple Case display: Single Node Debugging
If the AI’s response doesn’t meet your expectations, use the "Prompt Editor" multiple times within a single LLM node to fine-tune its output. Refer to the example prompt below for implementation guidance:
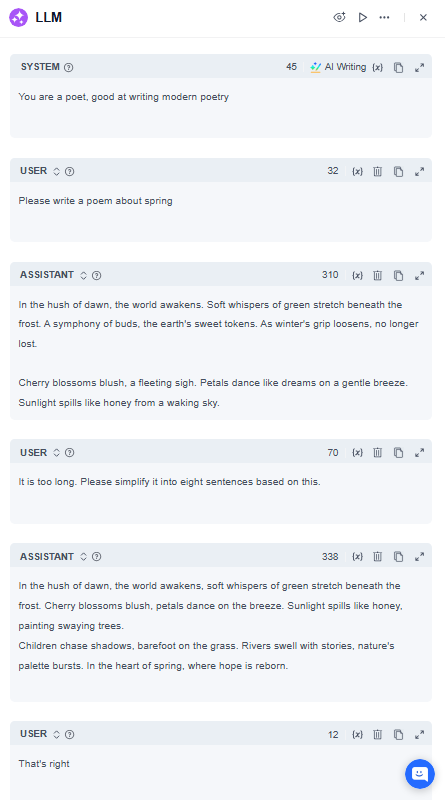
Note
- Avoid inserting the same variable in multiple section (e.g., inserting variable A in both the System and User boxes), as it might confuse the model.
- Large language models have input token constraints. It’s recommended to avoid inserting excessive content at once. For longer inputs, use knowledge base features to manage the extensive information effectively.
- For highly complex tasks with intricate steps, avoid processing everything with a single large model. Instead, use separate LLM nodes for each step to enhance output accuracy and reduce errors.
- Large models can produce inconsistent output at times. If results aren’t ideal, running multiple iterations or refining your prompt can lead to better outcomes.
Leave a Reply.