Definition
The JSON Variable Extractor node can extract specified fields (values) from input data in JSON format. This allows for parsing complex JSON strings and saving them as structured information that can be directly used by subsequent nodes.
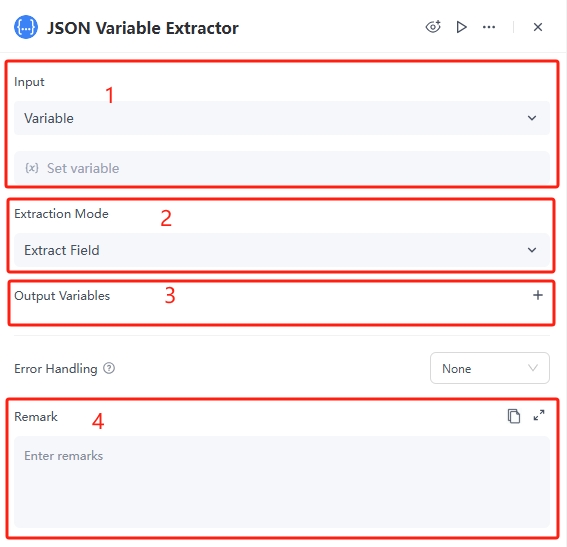
Quick Start / How to Use
Detailed instructions for configuring the node: Right-click in GoInsight.AI and select "Add Node" to add the 'JSON Variable Extractor' node to the workflow.
1. Configure the Value parameter of the JSON Variable Extractor node
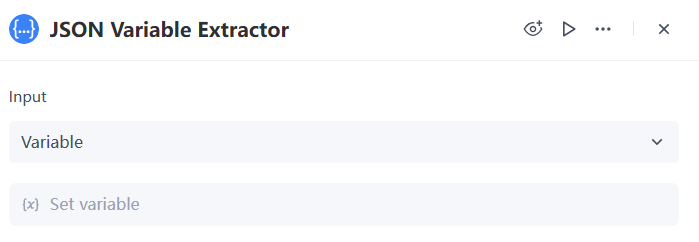
The "Input Value" has two options: "Variable" and "Value," as explained below:
| Option | Description |
|---|---|
| Variable | Retrieves JSON data from other existing variables in the workflow, suitable for scenarios where dynamic JSON data retrieval is needed. |
| Value | Inputs a static JSON string as the data source, suitable for cases where the JSON data is known and fixed. |
If "Input Value" is set to "Variable," you need to select an existing variable in "Set Variable Value," which should contain valid JSON format data; if "Value" is selected, you need to input a JSON formatted string in the text box. Example:
{
"name": "Scout",
"age": 18
}
2. Configure the Extraction Mode and Output Variable parameters of the JSON Variable Extractor node
The extraction modes include "Extract Field" and "Entire Output," corresponding to different output variable formats, as detailed below:
- Extract Field: Allows you to extract specific fields or nested field values from the JSON data.Output Variable: Click "+" to specify one or more output variables. Each output variable must include "Variable Name," "Target Field," and "Field Data Type."
- Entire Output: Outputs the entire JSON data as a single output without extracting any fields.Output Variable: Click "+" to add an output variable, which must include "Variable Name" and "Field Data Type."
- The options for Field Data Type:The output field data types cover common data formats found in JSON data, allowing users to extract and process different types of data as needed. Detailed descriptions are provided below:
| type | explanation |
|---|---|
| String | Used to store text information, such as names, addresses, etc. |
| Number | Used to store numerical information, which can be integers or floating-point numbers, such as age, price, etc. |
| Bool | Boolean type, with only two values: true and false, commonly used for logical judgments. |
| Array[Bool] | Array of Boolean types, used to store multiple Boolean values, such as a collection of task completion statuses. |
| Array[Number] | Array of numerical types, used to store multiple numbers, such as product prices, quantities, etc. |
| Array[Object] | Array of object types, used to store complex data structures, such as a list of user information. |
| Array[String] | Array of string types, which can contain multiple strings, such as multiple product names, city names, etc. |
| Object | Used to store data in key-value pair format, such as detailed user information, order details, etc. |
Typical Use Cases
Assuming the "Input Value" is set to "Value" for static input or "Variable" to select from existing variables, input the following JSON:
{
"name": "Scout",
"age": 18
}
If you want to extract the fields name and age from the JSON and store them in different variables:
1.Extraction Mode: Select "Extract Fields"
First Output Variable
- Variable Name: userName
- Target Field: name
- Field Data Type: String
Second Output Variable
- Variable Name: ageuserAge
- Target Field: age
- Field Data Type: Number
You can obtain the following two output variables:
{
"Outputs": [
{
"Name": "userName",
"Type": "string",
"Value": "Scout"
},
{
"Name": "ageuserAge",
"Type": "number",
"Value": 18
}
]
}
If you want to treat the entire JSON object as a single string, for example, when sending JSON data to internal and external systems.
2.Extraction Mode: Select "Whole Output"
Output Variable
- Variable Name: userInfo
- Field Data Type: Object
You can obtain two output variables:
{
"Outputs": [
{
"Name": "userInfo",
"Type": "object",
"Value": {
"age": 18,
"name": "Scout"
}
}
]
}
3.The input JSON is a multi-level nested structure.
For example, the following JSON is a multi-level nested structure:
{
"user": {
"name": "Scout",
"info": {
"age": 18,
"hobbies": ["read", "run"]
}
}
}
If you want to extract the "age" field, the extraction field name would be: "age", and the target field would be: $.user.info.age
- In this instance of the JSON variable extractor node, $.user.info.ageis a generic path expression (JSONPath) used to specify the location of the field to be extracted within the multi-level nested JSON structure. Below is an explanation example of its origin:
| Symbol/Content | Explanation |
|---|---|
| $ symbol | $ represents the root node of JSON data and is the starting point of the path expression. No matter how complex the JSON structure is, the path expression always starts with $ |
| Dot (.) separates fields | The dot is used to separate different levels in the JSON object. Each dot is followed by the field name of the current level. |
The JSON Variable Extractor node supports standard JSON Path syntax. If you need to use more complex extraction syntax, you can refer to this document. It is important to note that this node only supports extracting wrapped string values using double quotes "..." and does not support single quotes '...'. For example, in a conditional filtering scenario [?(@.field == "value")], the value must be enclosed in double quotes in order to be extracted successfully.
Practical Scenario Case
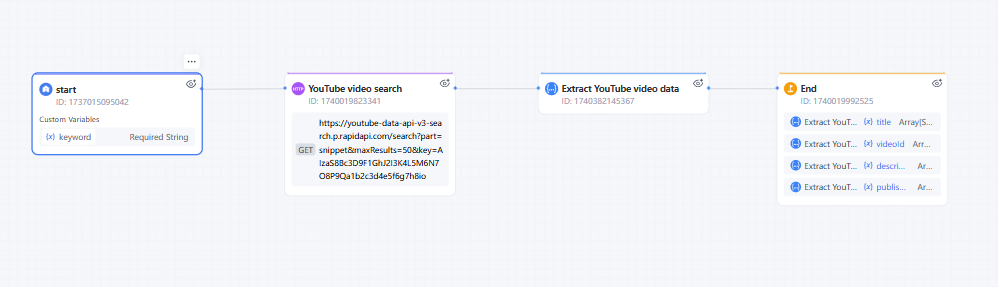
Steps to Filter YouTube Video Workflow:
- 1. Enter the keyword in the start node.
- 2. Enter the API information in the HTTP node to search for the corresponding YouTube videos using the keyword.
- 3. Since the HTTP response may contain a lot of video information, use the JSON Variable Extractor node to extract the titles, publish times etc. needed, filtering out other information.
This way, we can directly obtain the titles, publish times, and other information about the YouTube videos we want.
Common Questions
Check if any of the following situations exist:
- Loading a large JSON file all at once (e.g., 100MB+ log files).
- Extracting too many redundant fields.
- Repeatedly parsing the same structured data.
Leave a Reply.