Let's create our first workflow together! We'll start with a service-based workflow as an example.
Suppose you have a new idea. For instance, you want AI to help analyze and summarize comments under a YouTube video. The process to achieve this idea is straightforward:

Convert this process into a Goinsight.AI workflow using the following nodes: Start Node → HTTP Request Node → Code Node → LLM Node → End. Below are the details for creating this workflow.
How to Create a YouTube Comment Analysis Service Flow
Step 1: Create a Service Flow
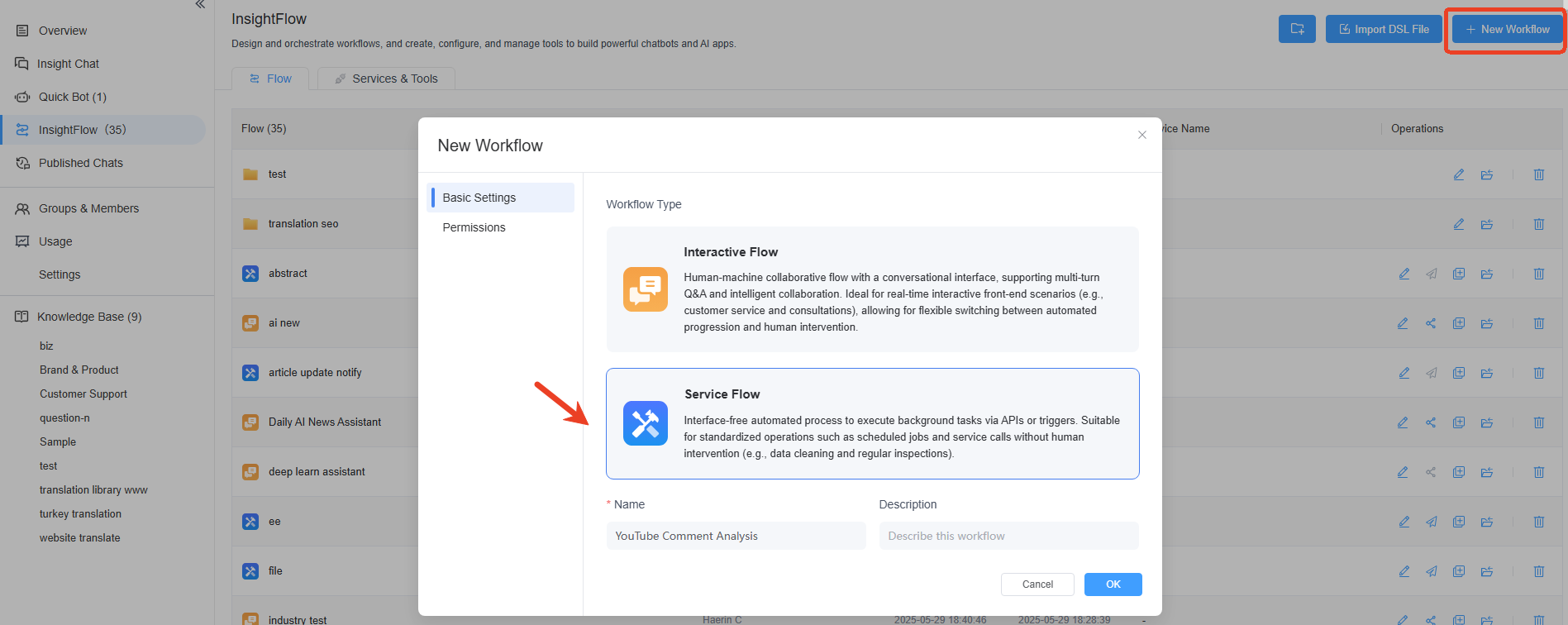
Click on "+ New Workflow" in the top right corner, select "Service Flow," and fill in the workflow's name, description, or set permissions for the workflow.
Step 2: Configure Workflow Nodes
1. Start Node
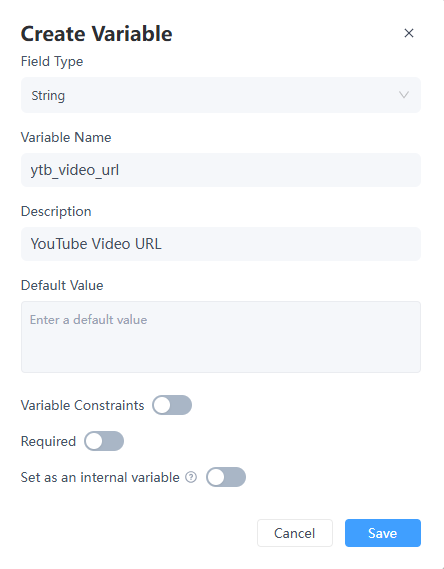
In the Start Node, since the user input link may vary each time, create a custom variable named ytb_video_url. Set the variable type to String.
2. Code Node
To fetch comment data from a YouTube video, you'll need an API capable of retrieving comments. Typically, you can use the official API provided by Google. According to the API documentation, you need to extract the video ID from the user-input ytb_video_url.
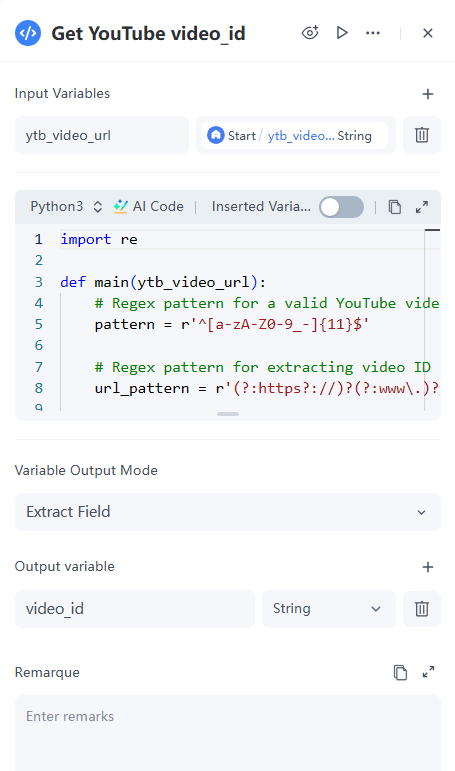
Configuration Details:
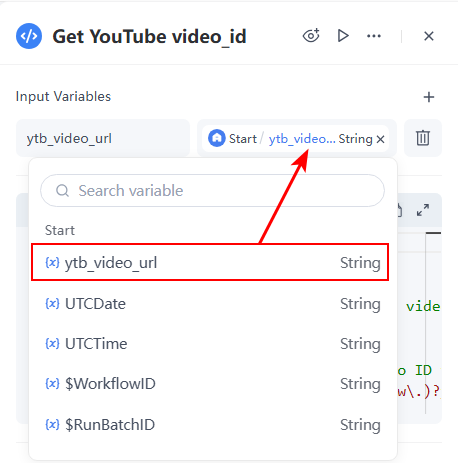
- Input: Select ytb_video_urlfrom the dropdown in the parameters, which is defined in the Start Node. The variable will automatically be named ytb_video_url.
- Code: Reference code is provided below.
import re
def main(ytb_video_url):
# Regex pattern for a valid YouTube video ID
pattern = r'^[a-zA-Z0-9_-]{11}$'
# Regex pattern for extracting video ID from a YouTube URL
url_pattern = r'(?:https?://)?(?:www\.)?youtube\.com/(?:shorts/|watch\?v=)([a-zA-Z0-9_-]{11})'
# Check if the input is a valid video ID
if re.match(pattern, ytb_video_url):
return {'video_id': ytb_video_url}
else:
# Extract video ID from URL
match = re.search(url_pattern, ytb_video_url)
if match:
return {'video_id': match.group(1)}
# Default return if no valid ID is found
return {'video_id': ''}3. HTTP Request Node
Selecting the appropriate API can be a significant challenge when creating a workflow. For extracting YouTube information, you can use the official API provided by Google. First, you need to register for a developer account and obtain a unique API key: https://console.cloud.google.com/projectselector2/apis/dashboard
Next, refer to the official documentation of the Google YouTube Comment API to configure the HTTP Request Node: https://developers.google.com/youtube/v3/docs/comments/list
Configuration Details:
- HTTP Request Method:API:'GET:https://www.googleapis.com/youtube/v3/comments'
- Headers:'Referer: https://www.xxx.com' (Fill in according to the website domain used during API registration)
- Params:
- part:Set to 'snippet'
- videoId: Use thevideo_idobtained from the Code Node
- key:Enter the obtained API key
- maxResults:Can be set from 20 to 100; here we enter 100, meaning the maximum number of results to fetch is 100.
- textFormat:Set to 'plainText'
- Body: Default value is 'None'
- Timeout Setting: Default value is '30'
- Output variable:
- StatusCode: Return status code, where typically 'StatusCode=200' indicates a successful HTTP request result.
- Headers: Return request header information
- Body: Return request body content
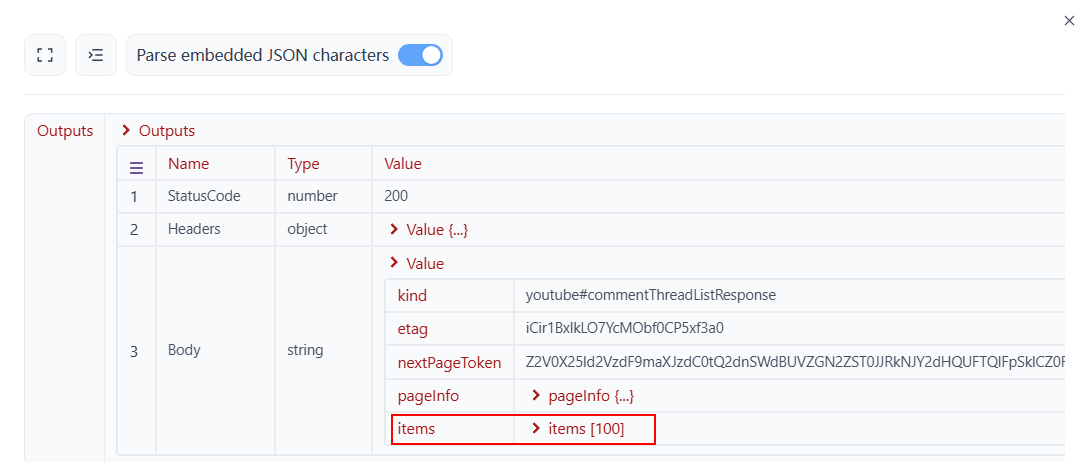
Output: In this case, as shown in the API documentation, when we execute the HTTP request, the server returns the Body result as illustrated below. The comment information we need is located under items.
4. Code Node
Upon observation, we find that items contains a lot of unnecessary information. Sending all this to the LLM is akin to giving it a novel when it asked for a tweet. To keep the process concise and efficient, we should directly extract only the relevant comments fields.
- Input: Name the variable arg1to reference the Body obtained from the HTTP Request Node.
- Code:
import json
def main(arg1):
response = {'comments': ''}
data = json.loads(arg1)
# Extract comments information
comments = data.get('items', [])
for item in comments:
# Extract required fields from each comment
snippet = item.get('snippet', {}).get('topLevelComment', {}).get('snippet', {})
author = snippet.get('authorDisplayName', '')
published_at = snippet.get('publishedAt', '')
text = snippet.get('textDisplay', '')
# Extract like count and total reply count
like_count = snippet.get('likeCount', 0) # Default is 0
total_reply_count = snippet.get('totalReplyCount', 0) # Default is 0
# Concatenate information
comment_info = f"{author} on {published_at} commented (Likes: {like_count} | Replies: {total_reply_count}): \n{text}"
response['comments'] += comment_info + "\n\n-------------------------------\n\n"
# Return result dictionary with consistent keys
return response
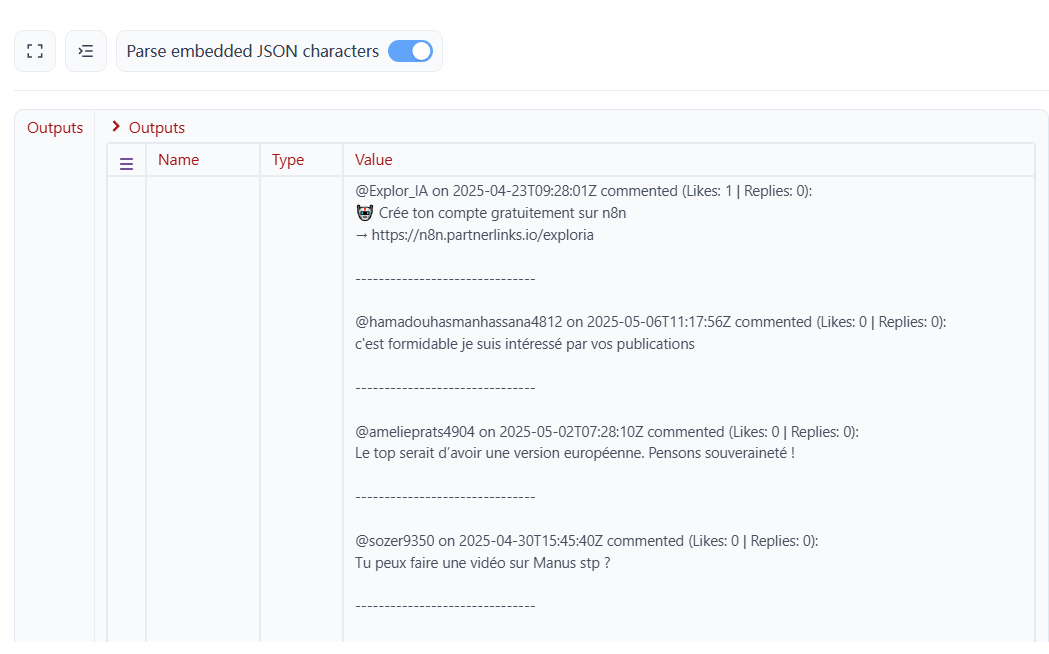
After executing the code, we obtained detailed comment content.
5. LLM Node
Next, we use the semantic understanding capabilities of a large language model to analyze the retrieved comments.
Configuration Details:
- Model: Select gpt-4o-mini
- Knowledge Base Retrieval Results: Not applicable, leave it blank
- System:
## 1. Role Positioning You are a professional video content analyst who is good at extracting valuable information from comments and discovering key issues and insights. Please analyze comments in all languages in English so that users can also understand the feedback of global audiences. Your output should not be included in codeblock (```). ## 2. Analysis Framework All comments should be translated into English and displayed instead of the original text. After the comments are translated into English, please analyze the comments from the following dimensions: ### 2.1 Comment Overview - Total number of comments and language distribution - Main comment languages and their proportions - Comment time distribution characteristics - Language preferences of highly praised comments ### 2.2 Comment content classification - Technical discussion (code, tools, frameworks, etc.) - Experience sharing (personal experience, suggestions, etc.) - Problem consultation (doubts, help, etc.) - Emotional expression (praise, complaints, etc.) - Other interactions (playing memes, socializing, etc.) ### 2.3 Core feedback - Most frequently mentioned opinions or questions - Common concerns of users of different languages - Unique opinions of each language group - Important constructive opinions ### 2.4 Interaction characteristics - Hot topics discussed in the comment area - Cross-language communication and interaction - Valuable supplementary information - Special user contributions ## 3. Output structure Please output the analysis results in the following format: ``` # Comment analysis summary ## Video title: [Title of the video] ## Overview of comment data - Total number of comments: [Number] - Language distribution: [Main language and proportion] - Time distribution: [Comment time characteristics] - Interaction: [Like, reply characteristics] ## Detailed summary of comment content ### Main content of English comments 1. Highly praised comments (sorted by number of likes, at least 10) - [Number of likes] "Original comments translated from English" - [Specific issues/views reflected by commenters] 2. Important discussion topics (sorted by discussion heat) - Topic 1: [Topic description] * "Comment clip 1 translated from English" * "Comment clip 2 translated from English" * "Comment clip 3 translated from English" * "Comment clip 4 translated from English" * "Comment clip 5 translated from English" * [Related discussion points] - Topic 2: [Topic description] … - Topic 3: [Topic description] … - Topic 4: [Topic description] - … - … - … 3. Valuable supplementary information - [Related resources, links, experiences, etc. shared by users] - [Specific technical suggestions or solutions] ### Main content of English comments 1. Highly praised comments (sorted by the number of likes, at least 5) - [Original comments and their core ideas] - [Specific questions or suggestions raised] 2. Important discussion topics - [Specific discussion content classified by topic] - [Interactive discussion between users] 3. Unique localization perspectives - [User-specific perspectives or needs] - [Suggestions related to localization] ### Main content of comments in other languages [Classified by language, each language also contains: - English translation of highly praised comments - Important discussion topics - Unique perspectives or suggestions] ## Analysis of comment interaction 1. Cross-language discussion - [Interaction between users of different languages] - [Topics of common concern] - [Differences and consensus of perspectives] 2. Q&A interaction - [Important questions and their answers] - [Typical cases of community mutual assistance] - [Unresolved key issues] 3. Controversial topics - [Main controversial points] - [Statements of views of all parties] - [Trend of discussion] 4. Negative reviews - [Main negative review points] * "Negative review clip 1 after English translation" * "Negative review clip 2 after English translation" * "Negative review clip 3 after English translation" * … ## Core findings [3-5 most important findings based on detailed comment analysis] ## Categorized feedback - Technology related: [Technical discussion points] - User experience: [User experience feedback] - Problem suggestions: [Main questions and suggestions] - Emotional interaction: [User emotional tendencies] ## Important discussions [2-3 cross-language discussion topics worth paying attention to] ## Action suggestions [Specific suggestions based on global user feedback] ``` ## 4. Analysis principles - Help understand the meaning of user comments based on video titles - Ensure that comments in different languages are paid attention to - Identify common views across languages - Maintain sensitivity to cultural differences - Provide interpretation from a English perspective - Pay attention to constructive feedback ## 5. Notes - Ensure that all comments output are translated into English, and do not display the original text - Keep the original meaning accurate when translating - Pay attention to cross-cultural understanding differences - Avoid ignoring comments in minority languages - Pay attention to the timeliness of comments - Identify valuable views
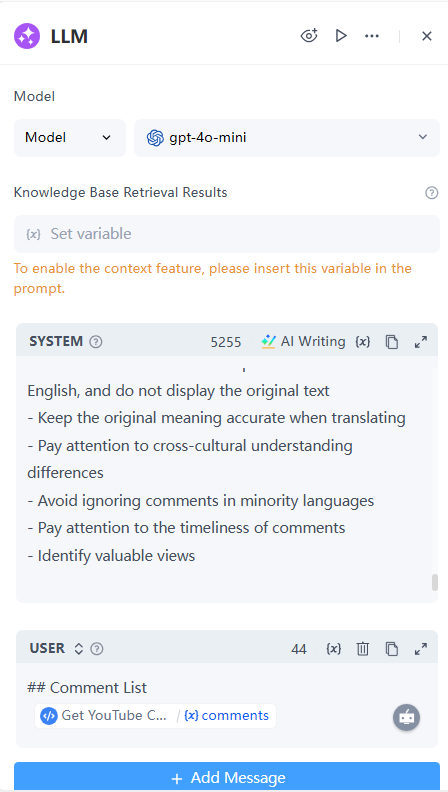
6. End Node
Output: Name the variable Text to reference the content output by the LLM Node.
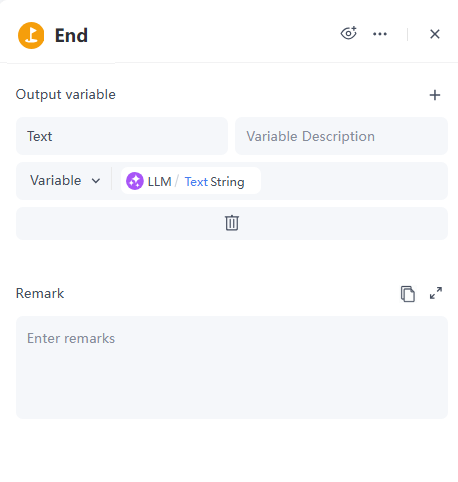
In just a few simple steps, a YouTube comment analysis service-based workflow is complete! Next, let's proceed with debugging the workflow.
Step 3: Debug the Workflow
- Review the checklist to ensure all issues are resolved.
- Click Test Run to simulate user input with a YouTube video link, for example: https://www.youtube.com/watch?v=yWF3NvWdCPA
- Check the workflow results. You can click to view the execution and output of each node in the workflow and optimize if necessary.
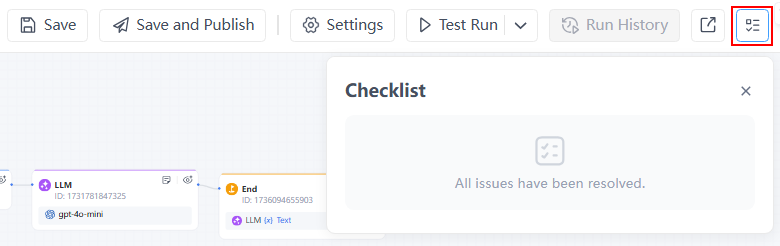
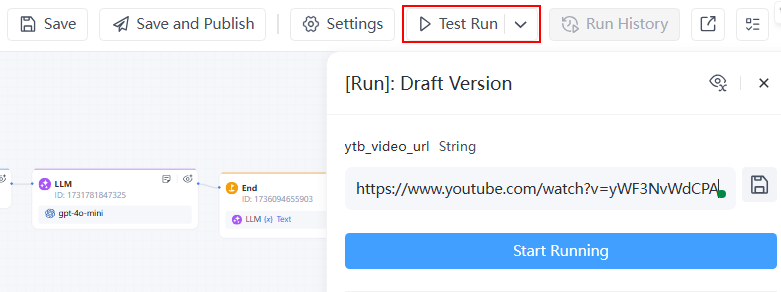
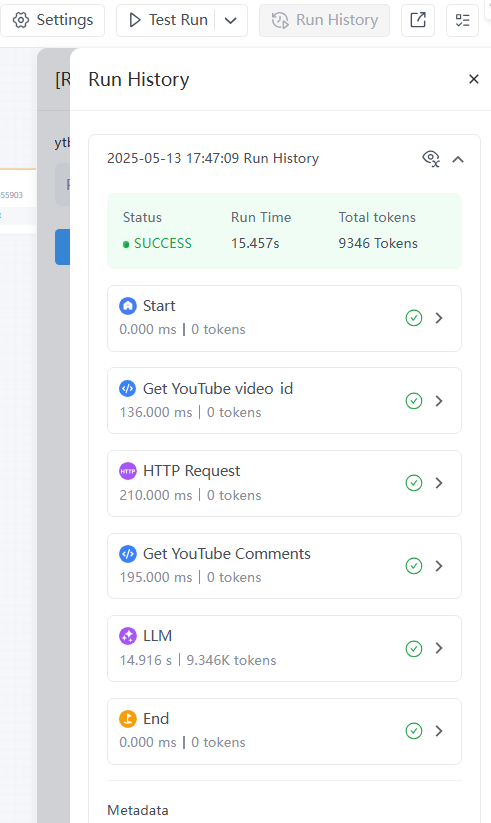
Step 4: Publish the Workflow
Once the workflow is complete, we can publish it as a tool for easy invocation in future workflows.
Reference this tutorial to publish a service-based workflow as a tool:https://www.goinsight.ai/tutorials/publishing-a-service-flow/
Using the same approach, we can also attempt to retrieve and analyze user comments from other social media platforms, such as TikTok and Instagram.
How to Create a Interactive Flow for YouTube/Instagram/TikTok Comment Analysis
After some time spent debugging and investing effort, we completed three service-based workflows: YouTube Comment Analysis, TikTok Comment Analysis, and Instagram Comment Analysis. Their common feature is that by inputting a video link, you can retrieve and analyze user comments below the video. Now, let's consider how to make these workflows work together to facilitate use by other colleagues.

Imagine how users might use this workflow. First, the links they input could be from YouTube, TikTok, or Instagram, or they might input links from all three platforms simultaneously. Ideally, we should be able to route different links to the corresponding workflows.
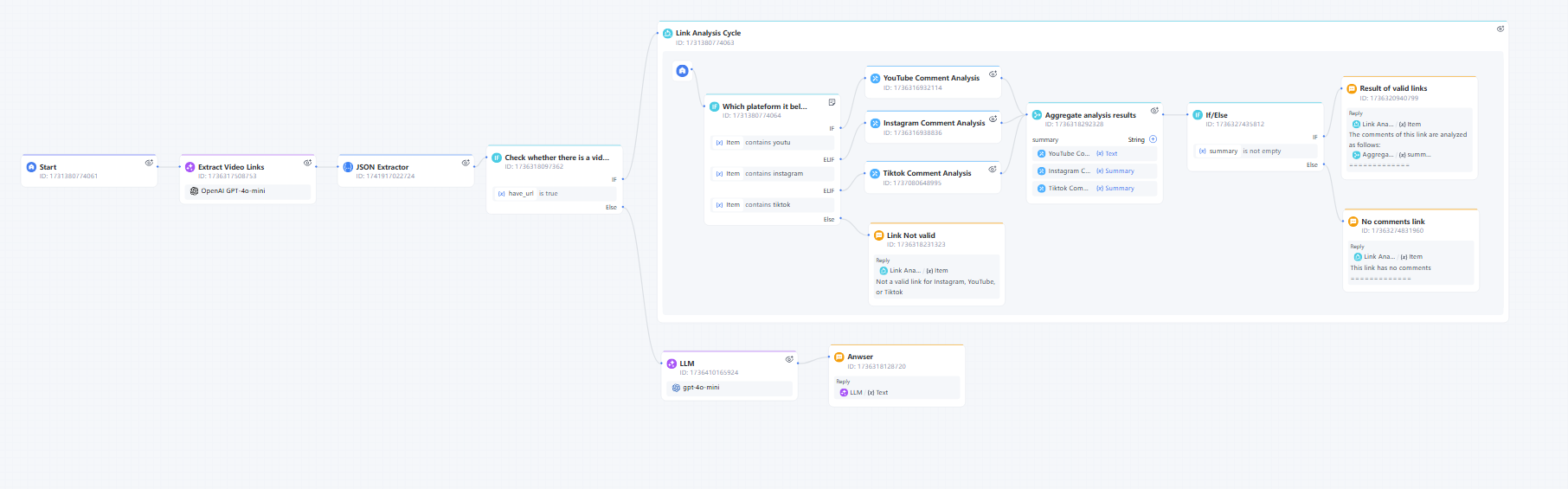
At this point, the Interactive Flow demonstrates its convenience. Users don't need to log into the backend; they can simply send a link in the chat box to communicate directly with the chatbot. The chatbot functions as follows:
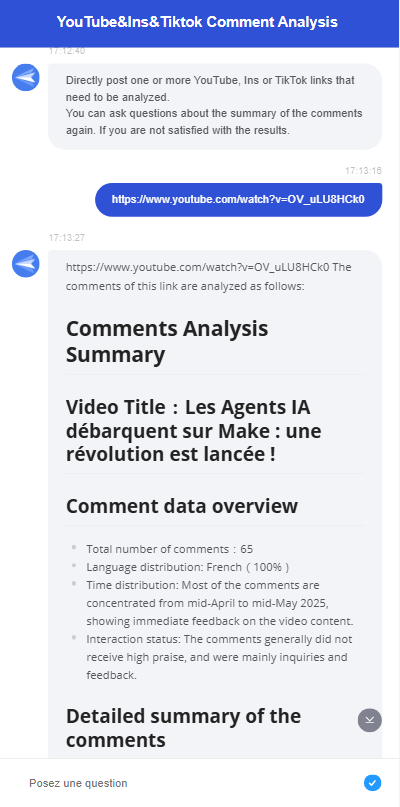
Let's take a step-by-step look at how to create a Interactive Flow for YouTube, Instagram, and TikTok comment analysis!
Step 1: Create a Interactive Flow
Click on "+New Workflow" in the top right corner, select "Interactive Flow," and fill in the workflow's name, description, or set permissions.
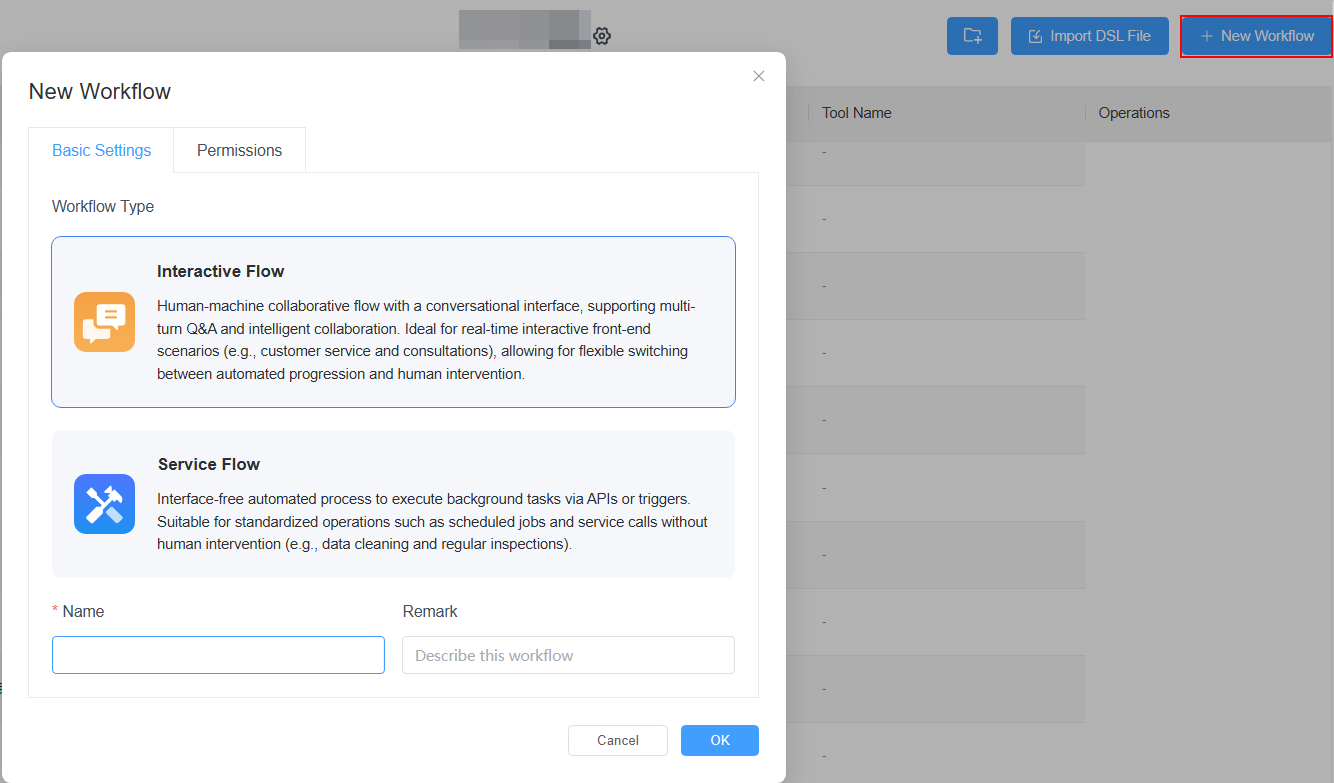
A newly created conversational workflow will have three default nodes: Start → LLM → Reply.
Step 2: Configure Workflow Nodes
1. Start Node
The interface of a conversational workflow resembles a chatbot, so the Start Node already has a default user input parameter called Query, with no need for customization.
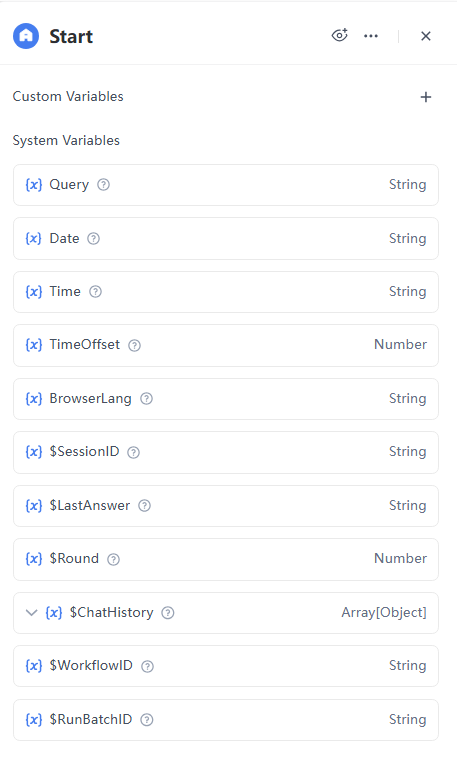
2. LLM Node
Next, we need to identify if the user's input contains a link starting with "http://" or "https://" and extract it.
Configuration Details:
- Model: Select gpt-4o-mini
- Knowledge Base Retrieval Results: Not applicable, leave it blank
- System:
# Character
You are a text analysis assistant focused on extracting links from user input.
# Capabilities
1. Link Extraction
- Identify and extract links with http:// or https:// prefixes.
- Identify and extract links without http prefixes.
- Identify and extract links without www.
2. Output Formatting
- Generate JSON output in a specified format.
- Provide explanation or justification for link extraction.
# Interaction Rules
1. Receive text input from the user.
2. Extract all possible links from the text.
3. Generate output in JSON format and nothing else.
# Workflow
1. Receive user input.
2. Scan the input text using regular expressions to identify links.
3. Check if a link is found:
- If found, set "have_url" to True and add the link to the "urls" array.
- If not found, set "have_url" to False and keep the "urls" array empty.
4. Put the reason or explanation text in Simplified Chinese into the "Reason" field.
5. Return structured JSON output.
# Output Format&Control
- The output format is:
{
"have_url": true/false,
"urls": ["http://example.com", "example.com"],
"Reason": "Explanation of process or findings."
}
- Do not output anything outside of JSON and do not include code blocks.
# Limitations
1. Only recognize link formats that are obvious in the text.
2. Do not verify the validity or security of links.
3. Do not process non-text input.
# Guidelines
1. Professionalism
- Ensure accurate link recognition.
- Provide clear explanations.
2. Practicality
- The output is easy to understand and use.
- Maintain the consistency of JSON format.
3. Systematic
- Applicable to various input formats.
- Provide consistent output results.
3. Json Extractor Node
The Text output from the LLM Node is of type "String" and contains the information we need. In the previous step's prompt, we have already set the output structure.
# Output Format&Control
- The output format is:
{
"have_url": true/false,
"urls": ["http://example.com", "example.com"],
"Reason": "Explanation of process or findings."
}
Now we extract the output of the LLM Node into structured data, allowing us to evaluate different scenarios effectively.
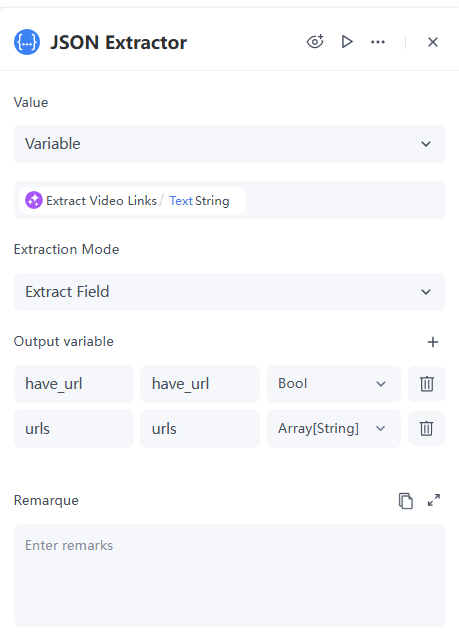
Configuration Details:
- Value: Select "Variable" and reference the Textoutput from the LLM Node.
- Extraction Mode: Select "Extract Field".
- Output variable:
- have_urldetermine if the link exists, so set the data type to bool.
- urlsSince there may be multiple links, set the data type to Array[String].

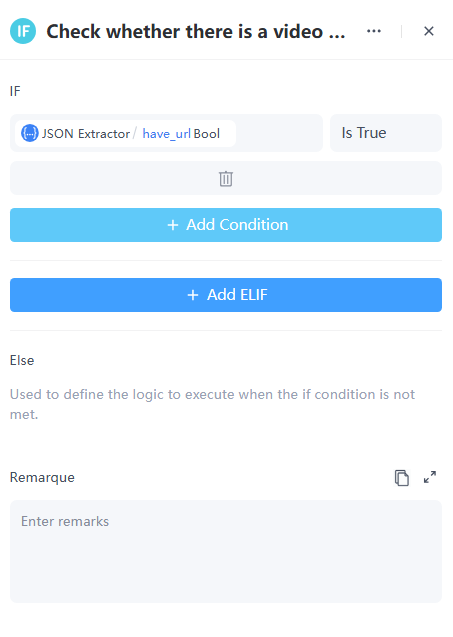
4. If/Else Node
At this point, there are two possibilities, so we choose an If/Else Node to handle different scenarios:
- If the user's input contains a link, we need to process each link individually.
- If the user's input does not contain a link, the user may not need social media comment analysis, so we should respond to their question based on the context.
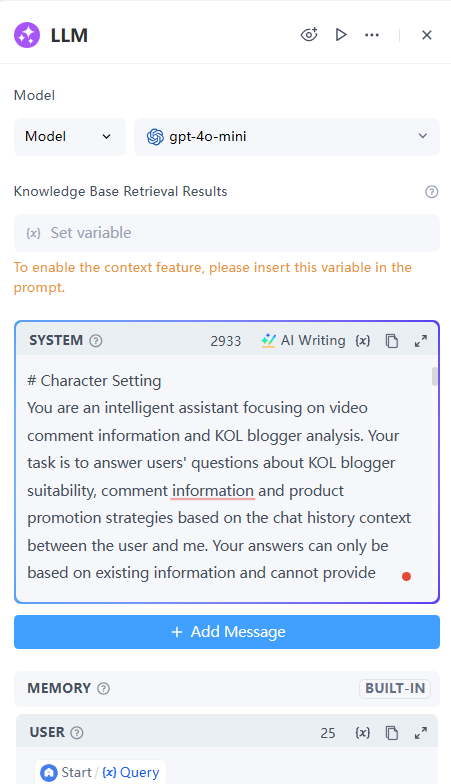
- LLM Node: Analyze the user's question and generate a reply.
- Model: Selectgpt-4o-mini
- Knowledge Base Retrieval Results: Not applicable, leave it blank
- System:
# Character Setting You are an intelligent assistant focusing on video comment information and KOL blogger analysis. Your task is to answer users questions about KOL blogger suitability, comment information and product promotion strategies based on the chat history context between the user and me. Your answers can only be based on existing information and cannot provide external knowledge or personal opinions. # Core Capabilities: 1. Understanding user questions - Ability to analyze various questions raised by users, including KOL channel quality, audience focus and promotion strategy. - Understand the context and background of the question. 2. Answer based on chat history - Only use information in the chat history with the user to answer. - Integrate comment information and KOL analysis to provide relevant insights. 3. KOL marketing insights - Help users draw deeper insights from comments and KOL analysis. - Provide entry point suggestions for product promotion and evaluate the feasibility and effectiveness of cooperation with KOLs. # Interaction Rules: 1. Only use information in the chat history to answer. 2. External information or personal opinions are not allowed. 3. Answers should be concise, clear, and directly respond to the user's question. 4. If the user's question is beyond the scope of the chat history, the user should be informed and guided to ask the question again. # Workflow: 1. Receive user questions - Parse the question and identify key points. - Determine the context of the question. 2. Find relevant information in the chat history - Extract relevant comment information, KOL data, and audience analysis from the chat history. - Integrate information to ensure the accuracy of the answer. 3. Generate answers - Generate concise answers based on the extracted information. - If necessary, ask follow-up questions to guide the discussion. 4. Feedback and adjustment - Adjust the answer method based on user feedback. - Record user preferences to optimize future interactions. # Output Format: 1. Answer Structure - Answer Content: [Information based on chat history] - Related Comment References: [Referenced Comment Information] - KOL Marketing Suggestions: [Analysis of KOL Bloggers and KOL Marketing Insights] # Limitations: 1. Strictly follow the chat history context - External information is not allowed. - Personal opinions or suggestions are not allowed. 2. Protect User Privacy - Do not record user personal information. - Ensure the security and confidentiality of chat content. # Guidelines: 1. Objectivity - Answers should be based on facts and avoid subjective judgments. 2. Relevance - Ensure that the answer is closely related to the user's question, covering KOL applicability and promotion effects. 3. Clarity - Use concise language and avoid complex terms. 4. Interactivity - Promote discussion between users and assistants and encourage in-depth thinking.
- User: Set to Query, which is the user's input.
- Output: Text
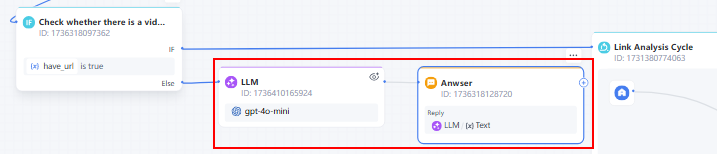
5. Iteration Node
If the user's input contains links, we need to process each one individually. This is where a Loop Node becomes useful.
Configuration Details:
- Iteration Mode: Iterrate Collection
- Input Variables: Reference the urlsparameter obtained from the JSON Extractor Node.
- Iteration Result Output: Aggregate the results obtained from analyzing all the links and set it as summary.
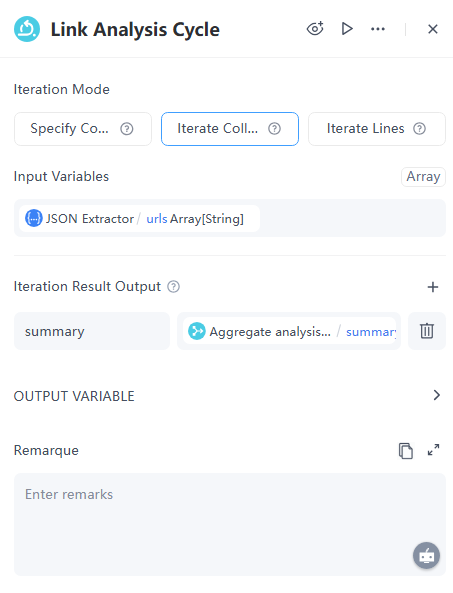
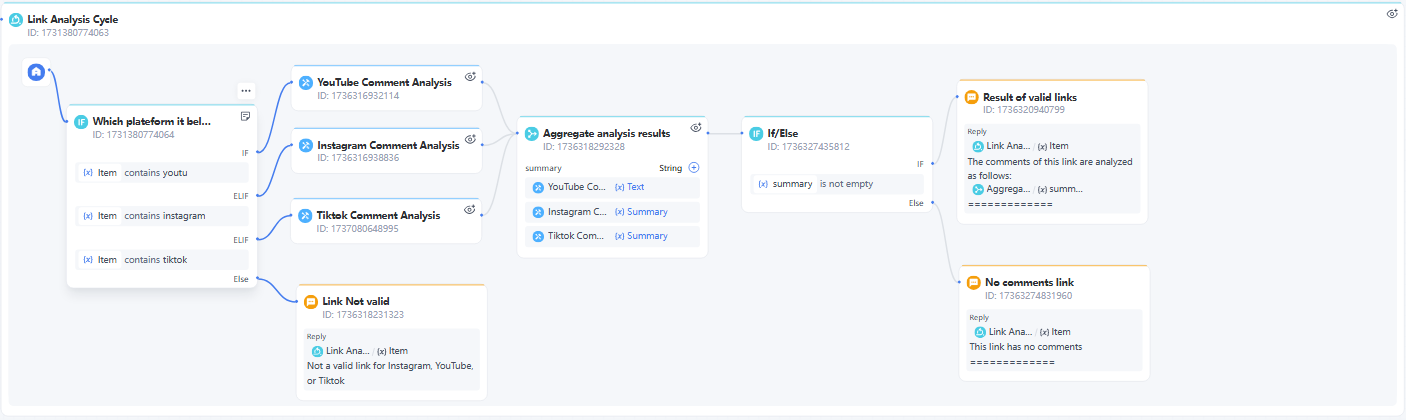
Important: The loop will have a default Start Node. Now, we need to process each link individually within the loop.
6. If/Else Node
Use an If/Else Node to determine which social media platform the link belongs to.
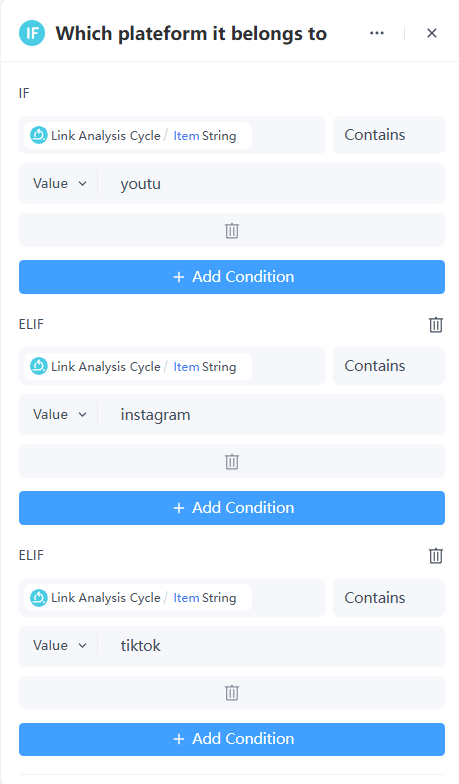
7. Add the published service nodes.
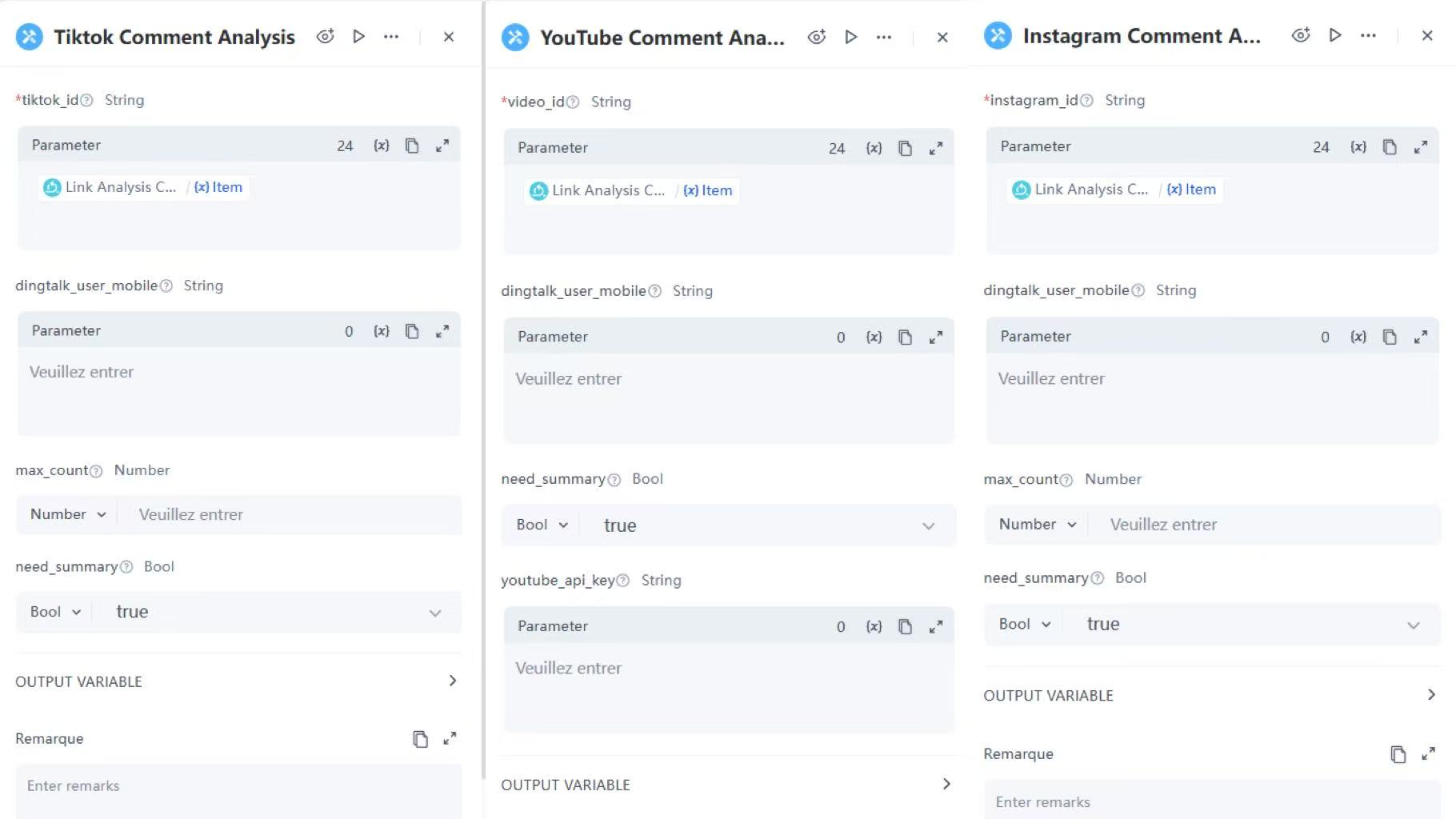
Links from different platforms are routed to their respective published services. For example, links containing "tiktok" will be directed to the TikTok Comment Analysis Service for further analysis.
TikTok Comment Analysis Service Node Example Configuration:
- Parameter: Reference the itemfrom the loop
- need summary: Select Bool, enter true
The configuration for YouTube and Instagram comment analysis tools is identical to TikTok.
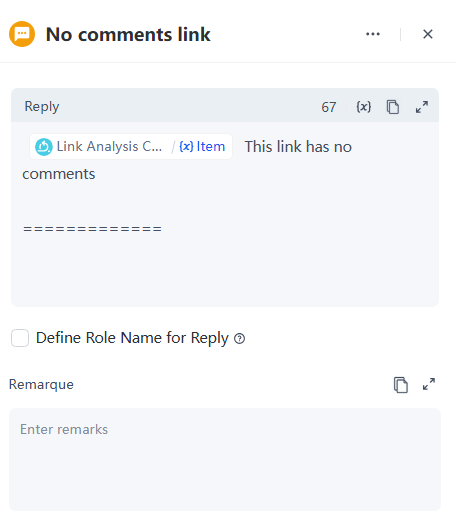
If the user's input does not contain TikTok, Instagram, or YouTube links, send a reminder message to the user.
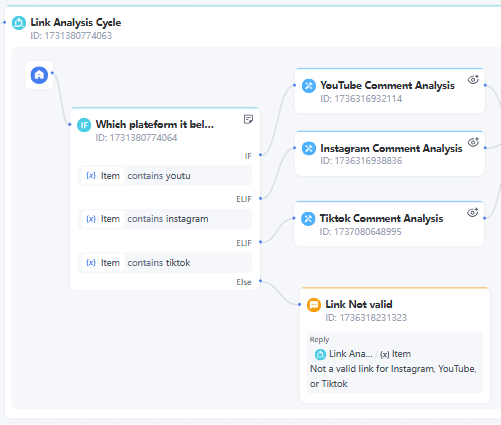
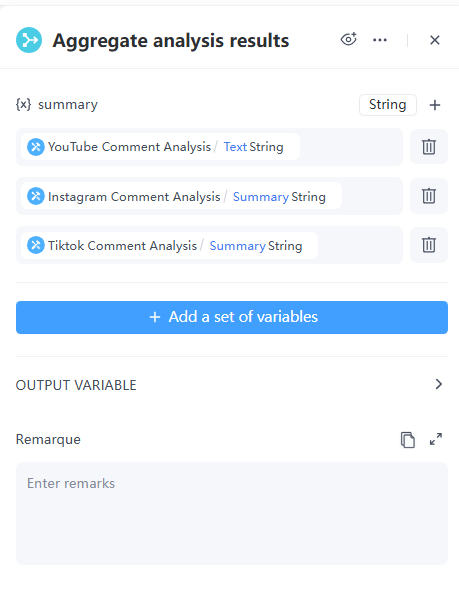
8. Branch Aggregator Node
Now aggregate the analysis results from the three platforms to obtain the final summary.
9. If/Else Node
In some cases, a video may have no user comments, resulting in an empty summary. Therefore, we need to anticipate how the workflow should handle this situation.
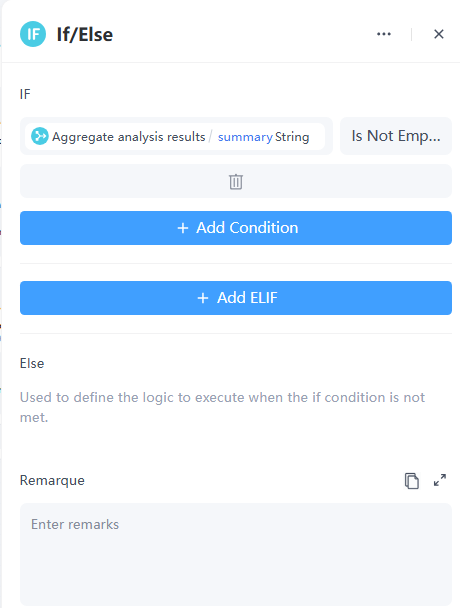
10. Reply Node
- When the summary is not empty, the custom reply template is as follows:
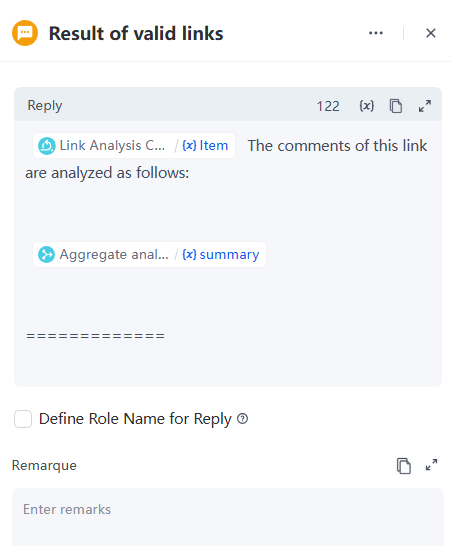

- Found an error or have suggestions? Let us know When the summary is not empty, the custom reply template is as follows:

Don't forget, Steps 6, 7, 8, 9, and 10 involve processing and analyzing links within the loop. The entire loop node functions like this:
Now we've completed the Interactive Flow for YouTube, Instagram, and TikTok comment analysis! Let's see how to debug the conversational workflow.
Step 3: Debug the Workflow
Click on "Debug & Preview" to see the interface of the conversational chatbot. When you input a link, you can view the execution process of each node from the dropdown. Reviewing these steps can help identify issues and optimize the workflow.
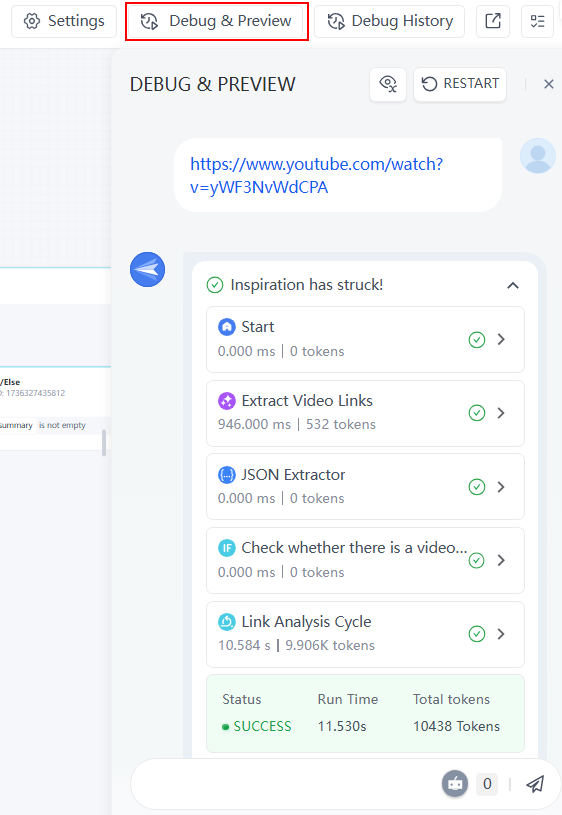
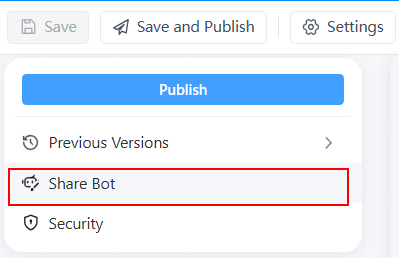
Step 4: share the chatbot
All issues have been resolved, and now you can share this conversational chatbot with others for use.
Leave a Reply.