定義
此自然語意變數提取器節點利用「大型語言模型」分析並解讀自然語言輸入,將使用者定義的變數參數提取為結構化格式。
如何配置
模型
從模型下拉選單中選擇您希望使用的大型語言模型。您可以調整語言模型的「溫度」參數,此參數決定模型回應的分歧(或隨機性)程度。較高的值會產生更具創意和多樣化的回應,而較低的值則會生成更集中且可預測的輸出。
詳細說明如下
| 配置選項 | 狀態 | 描述 |
|---|---|---|
| 溫度開關 | 關閉 | 模型的輸出遵循固定的機率分佈,結果更為穩定且具決定性。適用於需要高精確度和一致性的任務,例如參數提取和事實查詢。 |
| 溫度開關 | 開啟 | 啟用對輸出多樣性和隨機性的控制,因為模型的機率分佈取決於所選的溫度值。 |
| 溫度值 | 較高(接近 1) | 生成更具多樣性和創意的內容,變異性較高。適用於腦力激盪或開放式任務,但可能降低精確度和一致性。 |
| 溫度值 | 較低(接近 0) | 模型輸出較不發散,生成更集中且可預測的結果,隨機性較低。適用於需要精確且穩定輸出的任務,例如資料提取。 |
輸入變數:
此處指自然語言資料輸入的來源,可以是:
- 工作流程中起始節點的預設 {x}Query 變數
- 前一節點的輸出變數
提取參數:
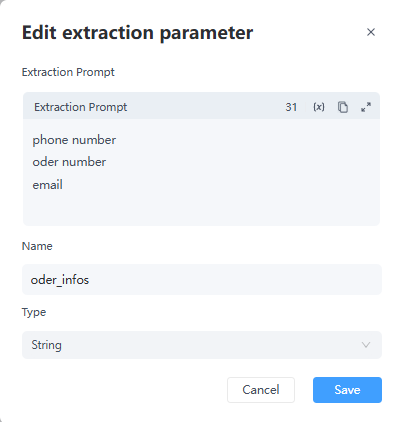
點擊「+」以新增並配置「提取參數」。每個參數需填寫 3 個欄位:「提取提示」、「名稱」和「類型」。
- 提取提示 (Extraction Prompt):提供要提取內容的清晰描述,並指定名稱(例如:「提取電話號碼」)。
- 名稱 (Name):為提取的資料定義自訂名稱或識別碼(例如:「customer-phone」)。
- 類型 (Type):指定輸出變數的資料類型(例如:「字串」、「Array[String]」)。
輸入文字範例為:「我的電話號碼是 123456,電子郵件是 xxxxxx@airdroid.com,訂單號碼是 987654。」此處的輸出範例如下:
| 類型 | 輸出 |
|---|---|
| 字串 | 「123456, xxxxxx@airdroid.com, 987654」 |
| Array[String] | [ "123456", "xxxxxx@airdroid.com", "987654" ] |
範例顯示
建議提供額外的提示,以協助模型更精確地提取複雜的變數。
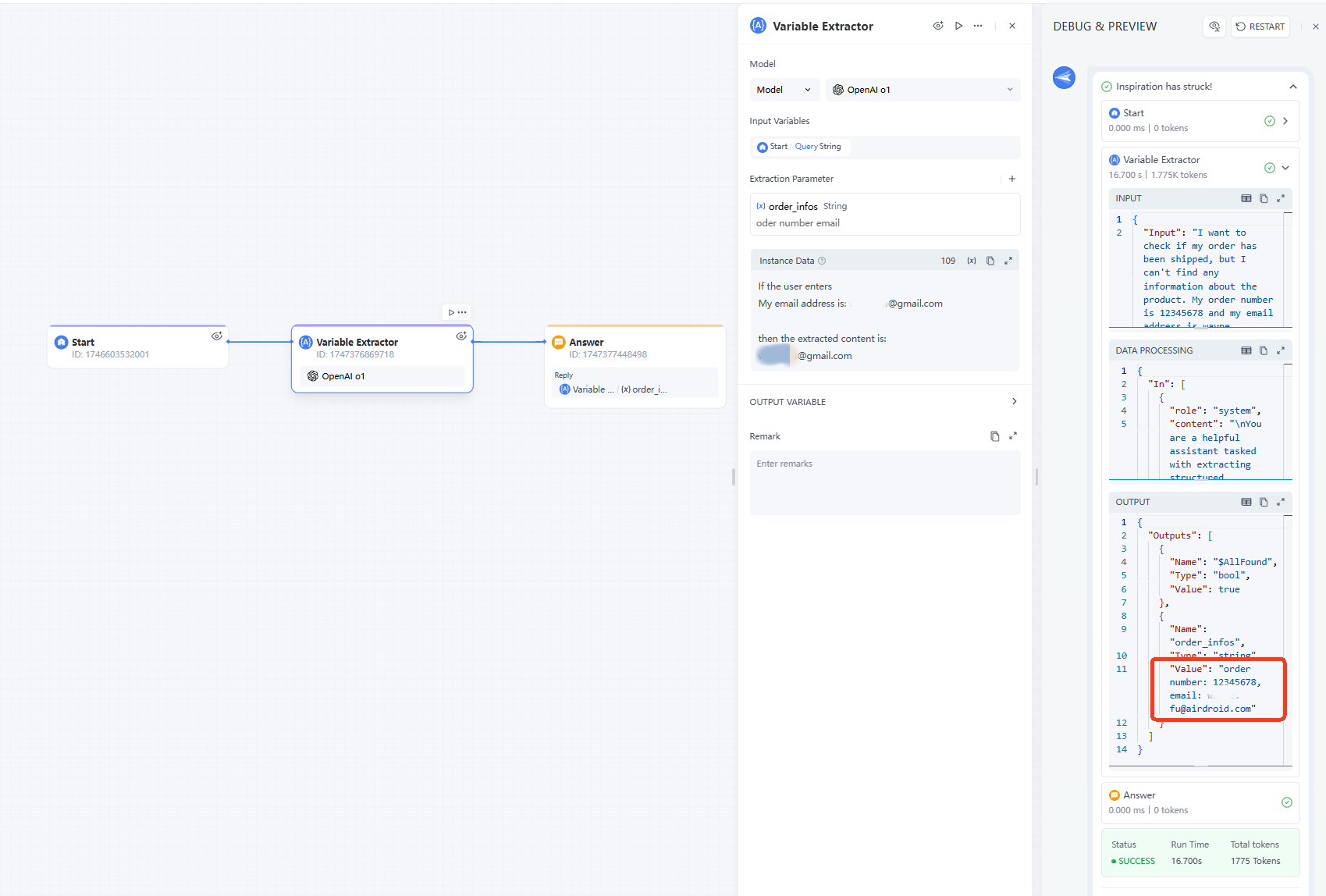
簡單案例 - 完整範例
使用案例(目標):從使用者輸入中提取重要或相關資訊。
起始節點:
變數提取器:依以下設定配置提取參數:
- 提取提示:訂單號碼、電子郵件
- 名稱:order_infos
- 類型:字串
使用者輸入範例:「我想查詢我的訂單是否已發貨,但找不到任何產品資訊。我的訂單號碼是 12345678,電子郵件是 xxxxxx@airdroid.com。請幫我找一下。」
回應輸出為:
- 「名稱」: "order_infos"
- 「類型」: "字串"
- 「值」: "12345678, xxxxxx@airdroid.com"
發佈評論