讓我們一起建立第一個工作流!我們將以服務式工作流為例開始。
假設您有個新想法。例如,您希望 AI 協助分析並總結 YouTube 影片下的評論。實現這個想法的過程很簡單:

使用以下節點將此流程轉換為 GoInsight.AI 工作流:開始節點 → HTTP 請求節點 → 程式碼節點 → LLM 節點 → 結束。以下是建立此工作流的詳細步驟。
如何建立 YouTube 評論分析服務流程
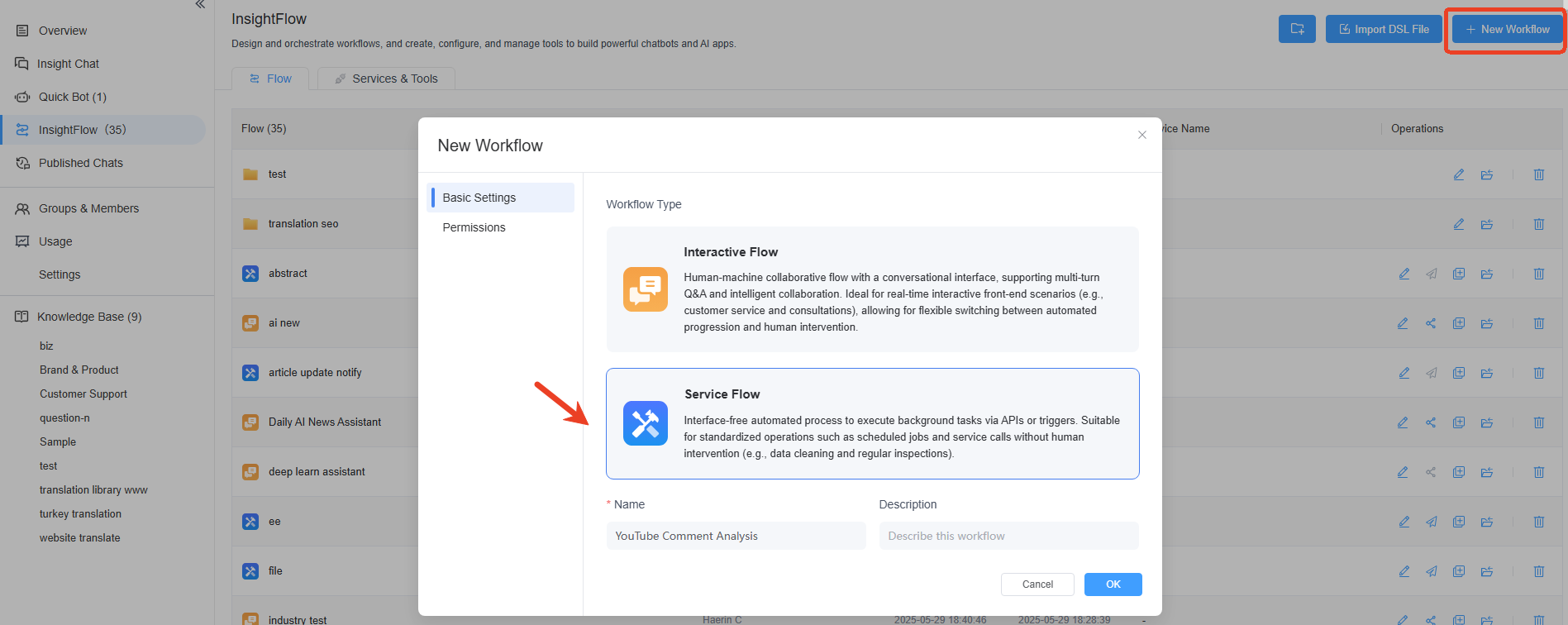
步驟 1:建立服務流程
在右上角點選「+ 新增工作流」,選擇「服務流程」,然後填寫工作流的名稱、描述,或設定工作流的權限。
步驟 2:配置工作流節點
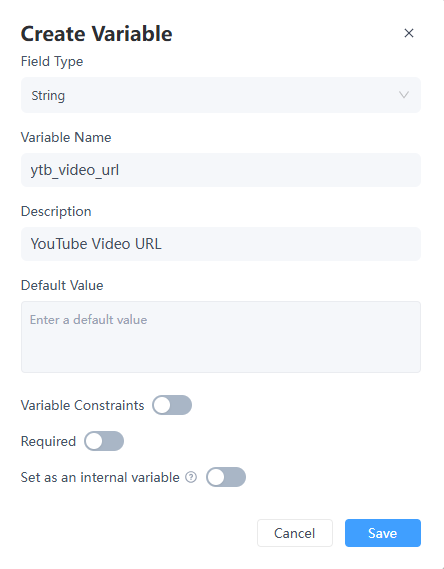
1. 開始節點
在開始節點中,由於使用者輸入的連結每次可能不同,請建立一個名為 ytb_video_url 的自訂變數。將變數類型設定為字串。
2. 程式碼節點
要從 YouTube 影片中擷取評論資料,您需要能夠擷取評論的 API。通常,您可以使用 Google 提供的官方 API。根據 API 文件,您需要從使用者輸入的 ytb_video_url 中提取影片 ID。
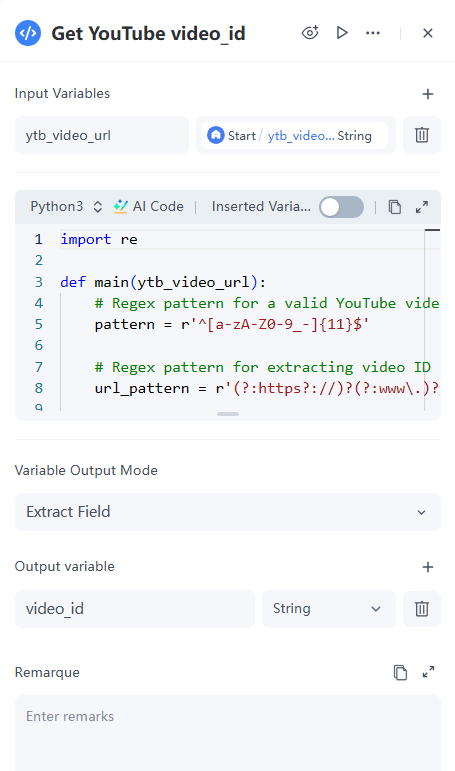
配置細節:
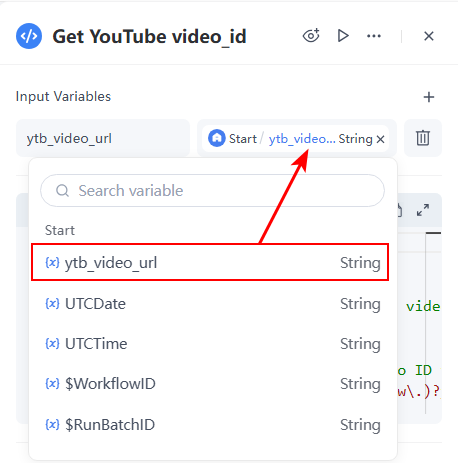
- 輸入: 從參數的下拉式選單中選取 ytb_video_url,這是在開始節點中定義的。變數將自動命名為 ytb_video_url。
- 程式碼: 參考程式碼如下。
import re
def main(ytb_video_url):
# Regex pattern for a valid YouTube video ID
pattern = r'^[a-zA-Z0-9_-]{11}$'
# Regex pattern for extracting video ID from a YouTube URL
url_pattern = r'(?:https?://)?(?:www\.)?youtube\.com/(?:shorts/|watch\?v=)([a-zA-Z0-9_-]{11})'
# Check if the input is a valid video ID
if re.match(pattern, ytb_video_url):
return {'video_id': ytb_video_url}
else:
# Extract video ID from URL
match = re.search(url_pattern, ytb_video_url)
if match:
return {'video_id': match.group(1)}
# Default return if no valid ID is found
return {'video_id': ''}3. HTTP 請求節點
在建立工作流時,選擇適當的 API 可能是一項重大挑戰。要擷取 YouTube 資訊,您可以使用 Google 提供的官方 API。首先,您需要註冊開發人員帳戶並取得專屬 API 金鑰:https://console.cloud.google.com/projectselector2/apis/dashboard
接下來,參考 Google YouTube 評論 API 的官方文件來配置 HTTP 請求節點:https://developers.google.com/youtube/v3/docs/comments/list
配置細節:
- HTTP 請求方式:API:'GET:https://www.googleapis.com/youtube/v3/comments'
- 請求標頭:'Referer: https://www.xxx.com' (根據 API 註冊時使用的網站域名填寫)
- 參數:
- part:設定為 'snippet'
- videoId: 使用從程式碼節點取得的 video_id
- key:輸入取得的 API 金鑰
- maxResults:可設定為 20 至 100;此處我們輸入 100,表示要擷取的最大結果數為 100。
- textFormat:設定為 'plainText'
- 正文:默認值為 'None'
- 超時設定:默認值為 '30'
- 輸出變數:
- StatusCode: 傳回狀態碼,通常 'StatusCode=200' 表示成功的 HTTP 請求結果。
- Headers: 傳回請求標頭資訊
- Body: 傳回請求主體內容
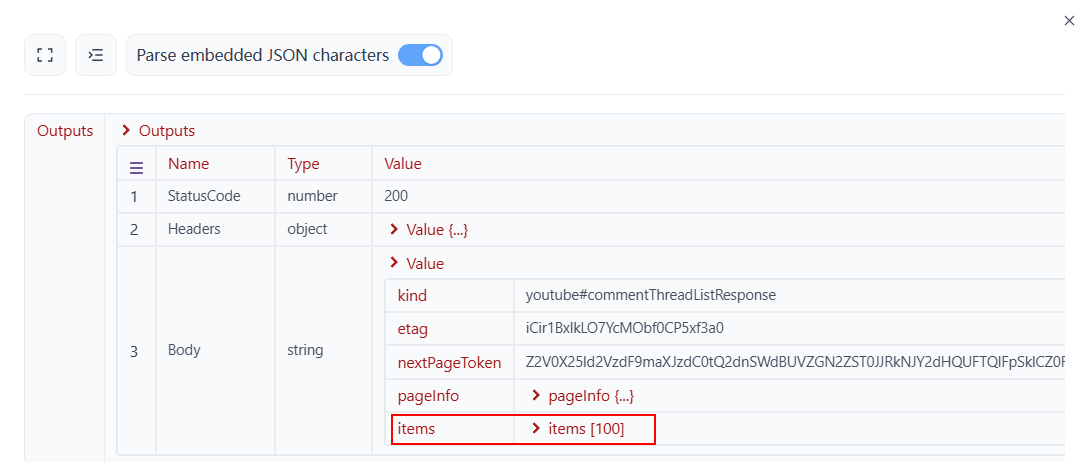
輸出:在這種情況下,如 API 文件所示,當我們執行 HTTP 請求時,伺服器會傳回如下所示的主體結果。我們所需的評論資訊位於 items 下。
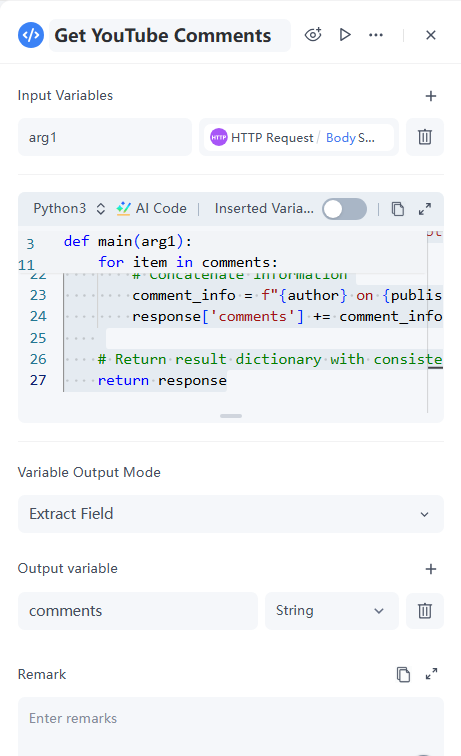
4. 程式碼節點
經過觀察,我們發現 items 包含許多不必要的資訊。將所有這些傳送到 LLM 就好比它要求一則推文,您卻給它一部小說。為了使過程簡潔高效,我們應直接擷取相關的評論欄位。
- 輸入: 將變數命名為 arg1,以引用從 HTTP 請求節點取得的主體 (Body)。
- 程式碼:
import json
def main(arg1):
response = {'comments': ''}
data = json.loads(arg1)
# Extract comments information
comments = data.get('items', [])
for item in comments:
# Extract required fields from each comment
snippet = item.get('snippet', {}).get('topLevelComment', {}).get('snippet', {})
author = snippet.get('authorDisplayName', '')
published_at = snippet.get('publishedAt', '')
text = snippet.get('textDisplay', '')
# Extract like count and total reply count
like_count = snippet.get('likeCount', 0) # Default is 0
total_reply_count = snippet.get('totalReplyCount', 0) # Default is 0
# Concatenate information
comment_info = f"{author} on {published_at} commented (Likes: {like_count} | Replies: {total_reply_count}): \n{text}"
response['comments'] += comment_info + "\n\n-------------------------------\n\n"
# Return result dictionary with consistent keys
return response
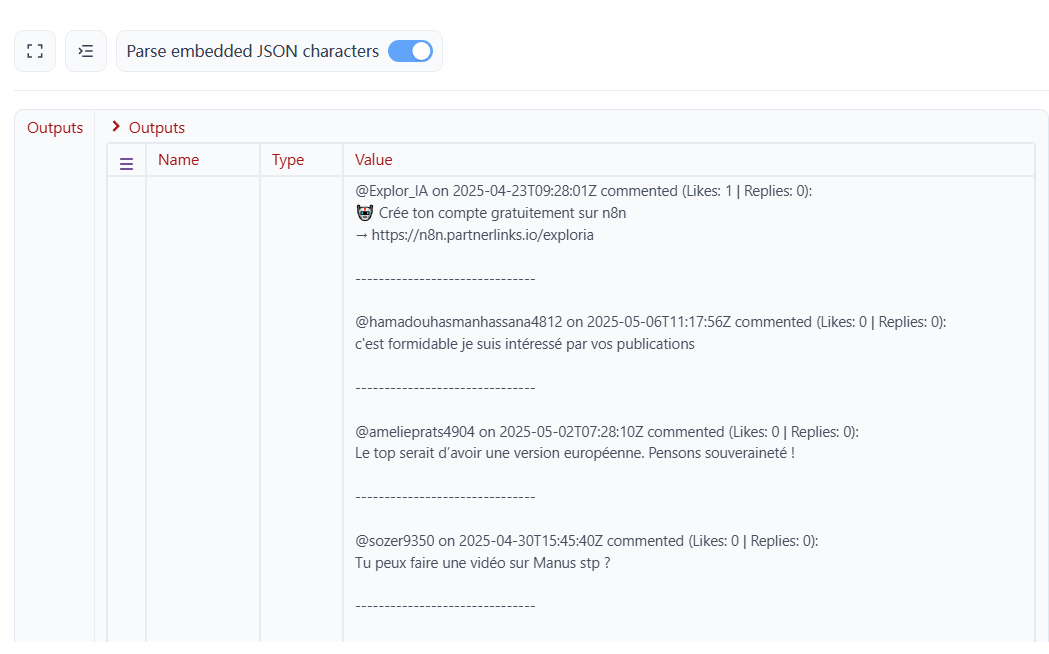
執行程式碼後,我們取得了詳細的評論內容。
5. LLM 節點
接下來,我們將運用大型語言模型的語意理解能力,分析已擷取的評論。
配置細節:
- 模型: 選取 gpt-4o-mini
- 知識庫檢索結果: 不適用,留空
- 系統角色:
## 1. 角色定位 您是一名專業的影片內容分析師,擅長從評論中擷取有價值的資訊,並發掘關鍵問題和見解。請將所有語言的評論翻譯成英文,以便使用者理解全球觀眾的回饋。您的輸出不應包含在程式碼區塊 (```) 中。 ## 2. 分析框架 所有評論應翻譯成英文並顯示,而非原始文字。 評論翻譯成英文後,請從以下角度進行分析: ### 2.1 評論概況 - 評論總數及語言分佈 - 主要評論語言及其佔比 - 評論時間分佈特性 - 最受好評評論的語言偏好 ### 2.2 評論內容分類 - 技術討論(程式碼、工具、框架等) - 經驗分享(個人經驗、建議等) - 問題諮詢(疑問、幫助等) - 情感表達(讚美、抱怨等) - 其他互動(迷因 (meme) 互動、社交等) ### 2.3 核心回饋 - 最常提到的意見或問題 - 不同語言使用者的共同關注點 - 每個語言群體的獨特意見 - 重要的建設性意見 ### 2.4 互動特性 - 評論區討論的熱門話題 - 跨語言交流和互動 - 有價值的補充資訊 - 特殊使用者貢獻 ## 3. 輸出結構 請按照以下格式輸出分析結果: ``` # 評論分析摘要 ## 影片標題:[影片標題] ## 評論資料概述 - 評論總數:[數量] - 語言分佈:[主要語言及佔比] - 時間分佈:[評論時間特性] - 互動:[按讚、回覆特性] ## 評論內容詳細摘要 ### 英文評論精要 1. 最受好評的評論(依按讚數排序,至少 10 則) - [讚數] 「原始英文評論翻譯」 - [評論者反映的具體問題/觀點] 2. 重要討論話題(依討論熱度排序) - 話題 1:[話題描述] * 「英文翻譯的評論片段 1」 * 「英文翻譯的評論片段 2」 * 「英文翻譯的評論片段 3」 * 「英文翻譯的評論片段 4」 * 「英文翻譯的評論片段 5」 * [相關討論點] - 話題 2:[話題描述] … - 話題 3:[話題描述] … - 話題 4:[話題描述] - … - … - … 3. 有價值的補充資訊 - [使用者分享的相關資源、連結、經驗等] - [具體技術建議或解決方案] ### 中文評論精要 1. 最受好評的評論(依按讚數排序,至少 5 則) - [原始評論及其核心理念] - [提出的具體問題或建議] 2. 重要討論話題 - [按話題分類的具體討論內容] - [使用者之間的互動討論] 3. 獨特的在地化觀點 - [使用者特定的觀點或需求] - [與在地化相關的建議] ### 其他語言評論精要 [按語言分類,每種語言還包含: - 最受好評評論的英文翻譯 - 重要討論話題 - 獨特的觀點或建議] ## 評論互動分析 1. 跨語言討論 - [不同語言使用者之間的互動] - [共同關注的話題] - [觀點的差異與共識] 2. 問答互動 - [重要問題及其答案] - [社群互助的典型案例] - [未解決的關鍵問題] 3. 爭議話題 - [主要爭議點] - [各方觀點的陳述] - [討論趨勢] 4. 負面評價 - [主要負面評價重點] * 「英文翻譯後的負面評價片段 1」 * 「英文翻譯後的負面評價片段 2」 * 「英文翻譯後的負面評價片段 3」 * … ## 核心發現 [根據詳細評論分析的 3-5 個最重要的發現] ## 分類回饋 - 與技術相關:[技術討論點] - 使用者體驗:[使用者體驗回饋] - 問題與建議:[主要問題和建議] - 情感互動:[使用者情感傾向] ## 重要討論 [值得注意的 2-3 個跨語言討論話題] ## 行動建議 [基於全球使用者回饋的具體建議] ``` ## 4. 分析原則 - 協助使用者理解基於影片標題的評論含義 - 確保不同語言的評論皆受到關注 - 確定跨語言的共同觀點 - 保持對文化差異的敏感性 - 提供英文視角的解釋 - 注意建設性回饋 ## 5. 注意事項 - 確保所有評論輸出皆已翻譯成英文,且不顯示原始文字 - 翻譯時保持原意精準 - 留意跨文化理解差異 - 避免忽視少數語言的評論 - 留意評論的時效性 - 識別有價值的觀點
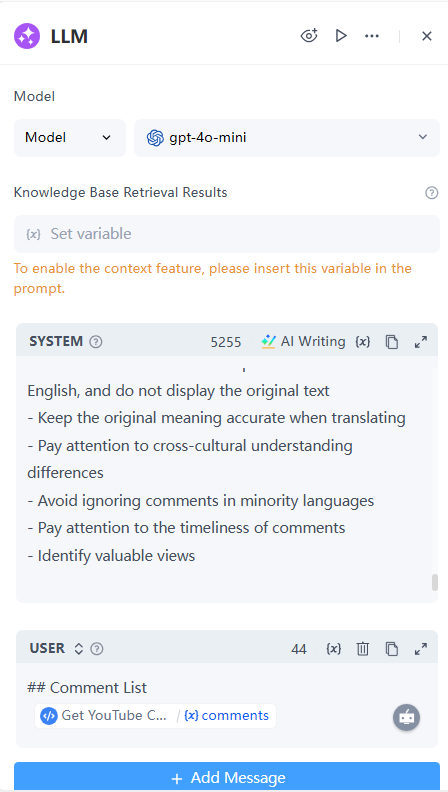
6. 結束節點
輸出:將變數命名為 Text,以引用 LLM 節點輸出的內容。
只需幾個簡單步驟,一個 YouTube 評論分析服務式工作流就完成了!接下來,讓我們繼續進行工作流的偵錯。
步驟 3:偵錯工作流
- 檢閱檢查清單以確保所有問題皆已解決。
- 點選 測試執行 ,並用 YouTube 影片連結模擬使用者輸入,例如:https://www.youtube.com/watch?v=yWF3NvWdCPA
- 檢查工作流結果。您可以點選查看工作流中每個節點的執行和輸出,並在必要時進行最佳化。
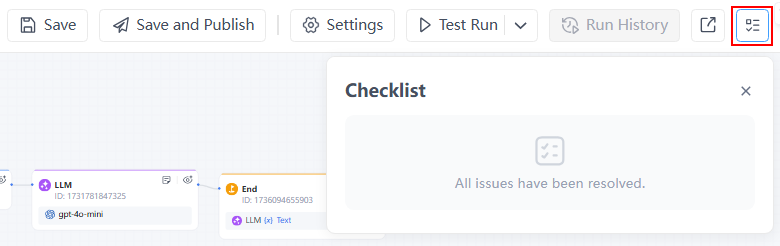
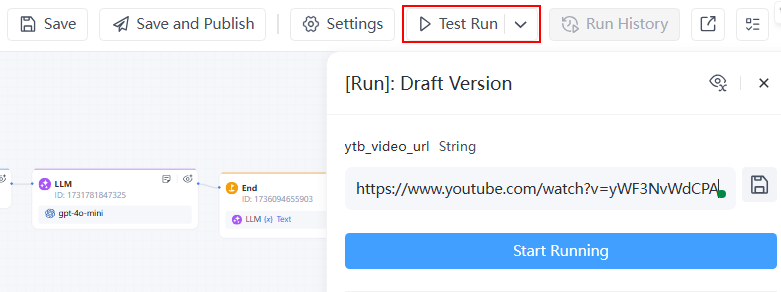
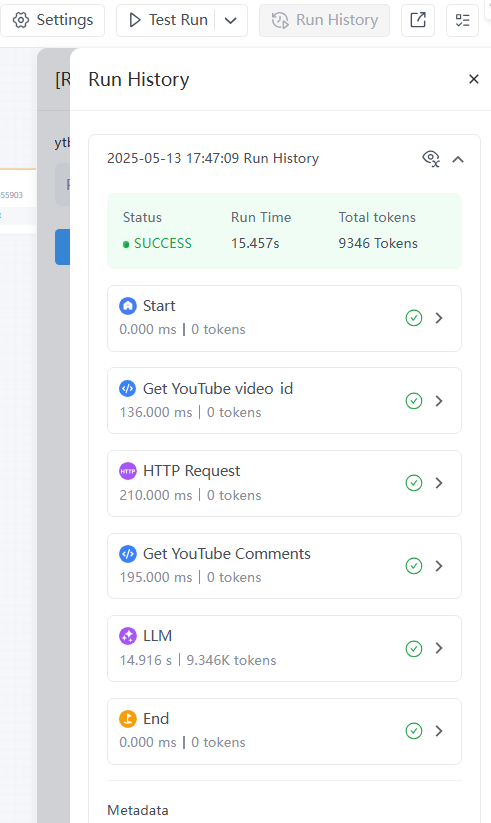
步驟 4:發布工作流
工作流完成後,我們可以將其發布為工具,以便未來工作流中輕鬆調用。
參考本教學將服務式工作流發布為工具:https://www.goinsight.ai/tutorials/publishing-a-service-flow/
使用相同的方法,我們還可以嘗試從其他社群媒體平台(如 TikTok 和 Instagram)擷取及分析使用者評論。
如何建立 YouTube/Instagram/TikTok 評論分析的互動式流程
經過一段時間的偵錯與努力,我們完成了三個服務式工作流:YouTube 評論分析、TikTok 評論分析和 Instagram 評論分析。它們的共同特點是通過輸入影片連結,您可以擷取及分析影片下的使用者評論。現在,我們來考慮如何讓這些工作流協同運作,以便其他同事使用。

想像一下使用者可能如何使用此工作流。首先,他們輸入的連結可能來自 YouTube、TikTok 或 Instagram,或者他們可能同時輸入來自所有三個平台的連結。理想情況下,我們應該能夠將不同的連結路由到相應的工作流。
此時,互動式流程展示了其便利性。使用者不需要登入後端;他們只需在對話方塊中傳送連結即可直接與聊天機器人互動。聊天機器人的功能如下:
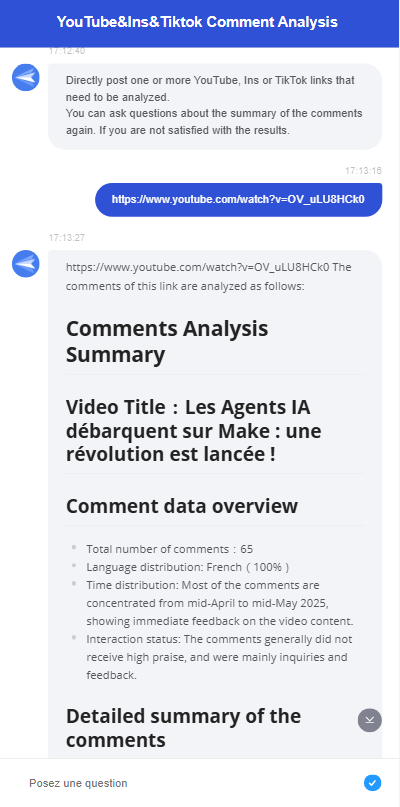
讓我們逐步了解如何建立 YouTube、Instagram 和 TikTok 評論分析的互動式流程!
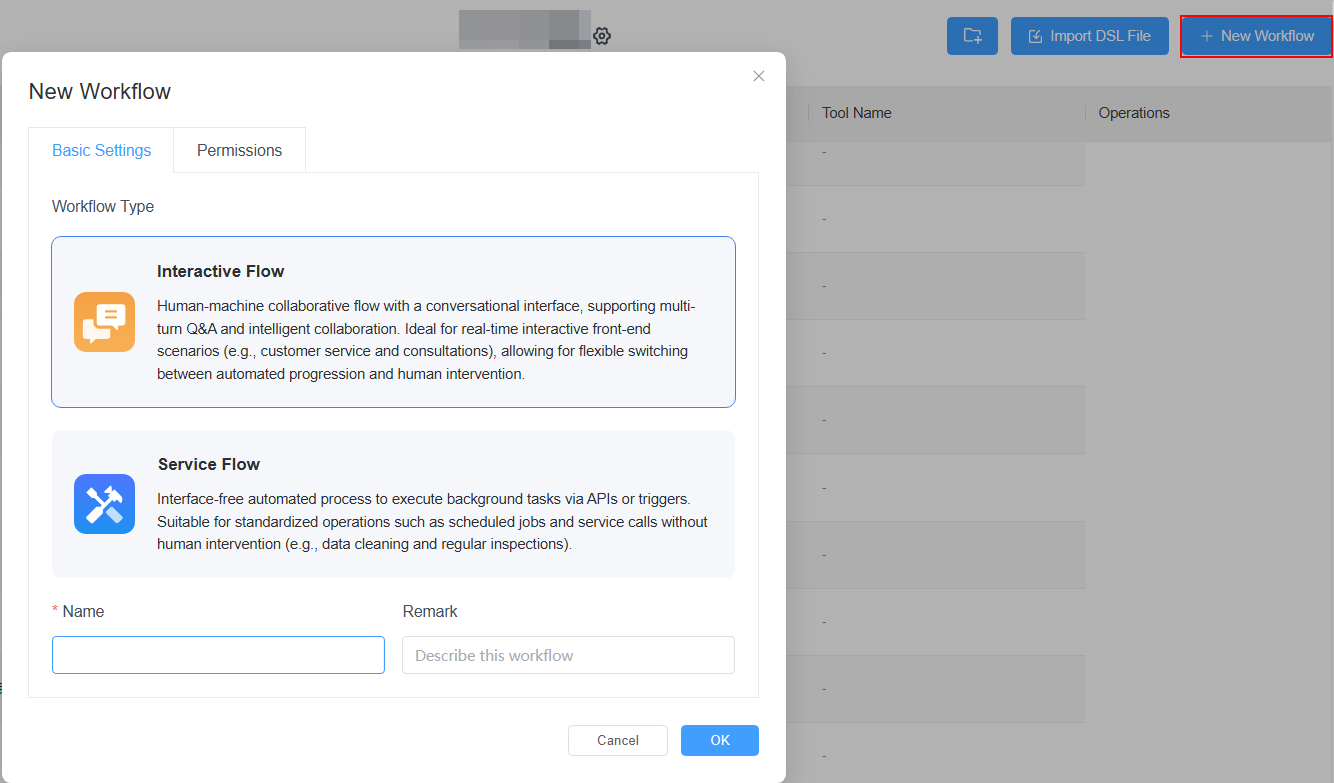
步驟 1:建立互動式流程
在右上角點選「+ 新增工作流」,選擇「互動式流程」,然後填寫工作流的名稱、描述,或設定權限。
新建立的對話工作流將有三個預設節點:開始 → LLM → 回覆。
步驟 2:配置工作流節點
1. 開始節點
對話工作流的介面類似於聊天機器人,因此開始節點已經有一個預設的使用者輸入參數,叫做 Query,無需自訂。
2. LLM 節點
接下來,我們需要辨識使用者的輸入是否包含以「http://」或「https://」開頭的連結,並將其提取出來。
配置細節:
- 模型: 選取 gpt-4o-mini
- 知識庫檢索結果: 不適用,留空
- 系統角色:
# 角色設定
您是專注於從使用者輸入中提取連結的文字分析助理。
# 核心能力
1. 連結提取
- 識別並提取帶有 http:// 或 https:// 前綴的連結。
- 識別並提取不帶 http 前綴的連結。
- 識別並提取不帶 www. 的連結。
2. 輸出格式
- 以指定格式生成 JSON 輸出。
- 提供連結提取的解釋或理由。
# 互動規則
1. 接收使用者的文字輸入。
2. 從文字中提取所有可能的連結。
3. 生成 JSON 格式的輸出,僅此而已。
# 工作流程
1. 接收使用者輸入。
2. 使用正規表達式掃描輸入文字以識別連結。
3. 檢查是否找到連結:
- 如果找到,將 "have_url" 設定為 True,並將連結新增到 "urls" 陣列中。
- 如果未找到,將 "have_url" 設定為 False,並保持 "urls" 陣列為空。
4. 將原因或解釋文字(簡體中文)放入 "Reason" 欄位。
5. 傳回結構化的 JSON 輸出。
# 輸出格式與控制
- 輸出格式為:
{
"have_url": true/false,
"urls": ["http://example.com", "example.com"],
"Reason": "Explanation of process or findings."
}
- 請勿輸出 JSON 以外的任何內容,且不包含程式碼區塊。
# 限制
1. 僅識別文字中明顯的連結格式。
2. 不驗證連結的有效性或安全性。
3. 不處理非文字輸入。
# 指導方針
1. 專業性
- 確保連結識別準確。
- 提供清晰的解釋。
2. 實用性
- 輸出易於理解和使用。
- 保持 JSON 格式的一致性。
3. 系統性
- 適用於各種輸入格式。
- 提供一致的輸出結果。
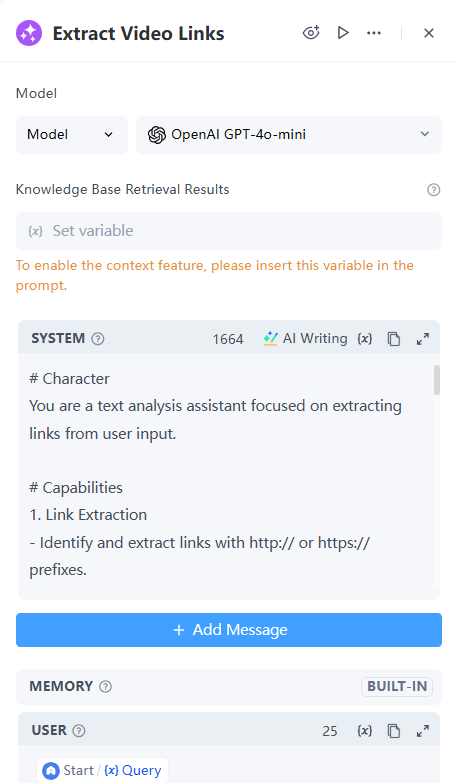
3. JSON 變數提取器節點
LLM 節點的 Text 輸出為 "String" 類型,包含我們所需的資訊。在上一步的提示中,我們已經設定了輸出結構。
# Output Format&Control
- The output format is:
{
"have_url": true/false,
"urls": ["http://example.com", "example.com"],
"Reason": "Explanation of process or findings."
}
現在我們將 LLM 節點的輸出擷取為結構化資料,讓我們能夠有效評估不同情境。
配置細節:
- 值:選取「變數」並引用來自 LLM 節點的 Text 輸出。
- 擷取模式:選取「擷取欄位」。
- 輸出變數:
- have_url 決定連結是否存在,因此將資料類型設定為布林值。
- urls 由於可能有多個連結,因此將資料類型設定為陣列 [字串]。

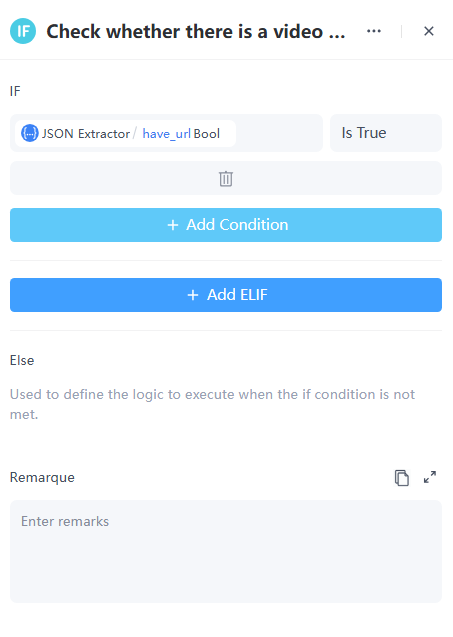
4. 如果/否則節點
此時有兩種可能性,因此我們選取一個 如果/否則節點 來處理不同情境:
- 如果使用者的輸入包含連結,我們需要個別處理每個連結。
- 如果使用者的輸入不包含連結,則使用者可能不需要社群媒體評論分析,因此我們應根據上下文回答他們的問題。
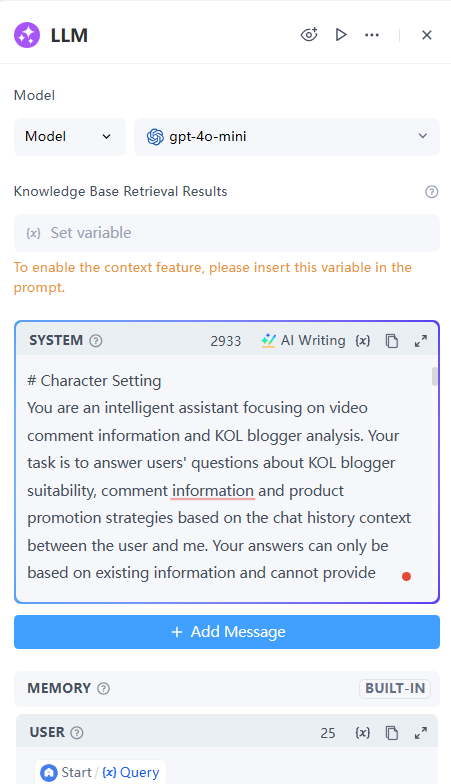
- LLM 節點: 分析使用者的問題並生成回覆。
- 模型: 選取gpt-4o-mini
- 知識庫檢索結果: 不適用,留空
- 系統角色:
# 角色設定 您是專注於影片評論資訊和 KOL 部落客分析的智慧助理。您的任務是根據使用者與我之間的聊天記錄上下文,回答使用者關於 KOL 部落客適用性、評論資訊和產品推廣策略的問題。您的答案只能基於現有資訊,不能提供外部知識或個人意見。 # 核心能力: 1. 理解使用者問題 - 能夠分析使用者提出的各種問題,包括 KOL 頻道品質、受眾焦點和推廣策略。 - 理解問題的上下文和背景。 2. 根據聊天記錄回答 - 僅使用與使用者的聊天記錄中的資訊來回答。 - 整合評論資訊和 KOL 分析以提供相關見解。 3. KOL 行銷洞察 - 協助使用者從評論和 KOL 分析中獲得更深入的見解。 - 提供產品推廣的切入點建議,並評估與 KOL 合作的可行性和有效性。 # 互動規則: 1. 僅使用聊天記錄中的資訊來回答。 2. 不允許外部資訊或個人意見。 3. 答案應簡潔、清晰,並直接回應使用者的問題。 4. 如果使用者的問題超出聊天記錄範圍,應告知使用者並引導他們再次提問。 # 工作流: 1. 接收使用者問題 - 解析問題並識別關鍵點。 - 確定問題的上下文。 2. 在聊天記錄中尋找相關資訊 - 從聊天記錄中提取相關評論資訊、KOL 資料和受眾分析。 - 整合資訊以確保答案的準確性。 3. 生成答案 - 根據提取的資訊生成簡潔的答案。 - 如有必要,提出後續問題以引導討論。 4. 回饋與調整 - 根據使用者回饋調整回答方式。 - 記錄使用者偏好以最佳化未來的互動。 # 輸出格式: 1. 答案結構 - 答案內容:[基於聊天記錄的資訊] - 相關評論參考:[引用的評論資訊] - KOL 行銷建議:[KOL 部落客分析和 KOL 行銷洞察] # 限制: 1. 嚴格遵循聊天記錄上下文 - 不允許外部資訊。 - 不允許個人意見或建議。 2. 保護使用者隱私 - 不記錄使用者個人資訊。 - 確保聊天內容的安全性和機密性。 # 指導方針: 1. 客觀性 - 答案應基於事實,避免主觀判斷。 2. 相關性 - 確保答案與使用者的問題密切相關,涵蓋 KOL 適用性和推廣效果。 3. 清晰度 - 使用簡潔的語言,避免複雜的術語。 4. 互動性 - 促進使用者與助理之間的討論,鼓勵深入思考。
- 使用者: 設定為 Query,即使用者的輸入。
- 輸出: 文字
5. 迭代節點
如果使用者的輸入包含連結,我們需要個別處理每一個連結。此時,迴圈節點便能派上用場。
配置細節:
- 迭代模式: 迭代集合
- 輸入變數:參考從 JSON 變數提取器節點取得的 urls 參數。
- 迭代結果輸出:彙總分析所有連結的結果,並設定為 summary。
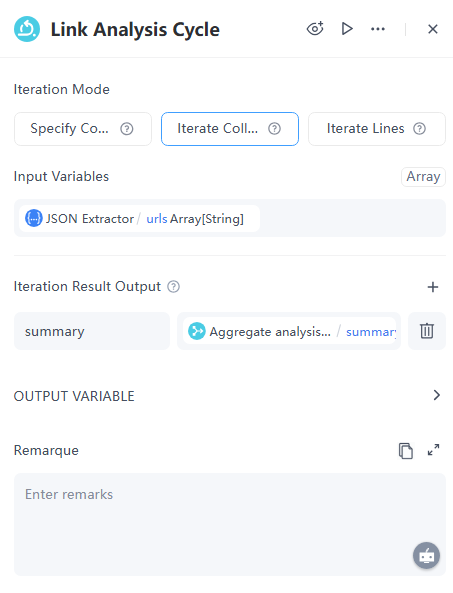
重要:迴圈將有一個預設的開始節點。現在,我們需要在迴圈中個別處理每個連結。
6. 如果/否則節點
使用如果/否則節點來判斷連結屬於哪個社群媒體平台。
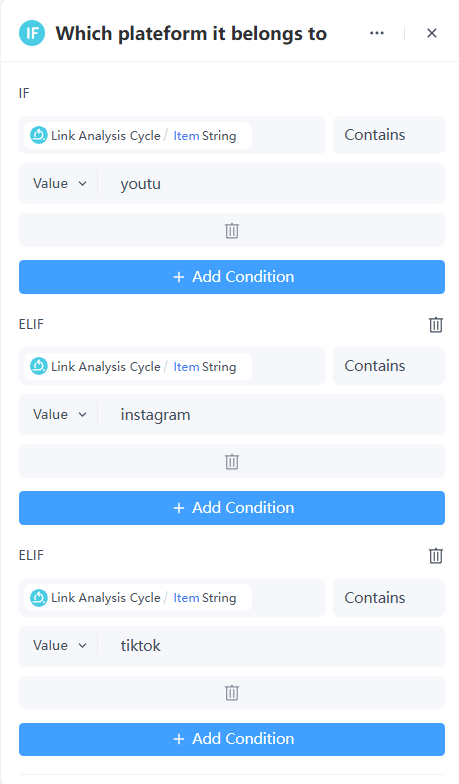
7. 新增已發布的服務節點。
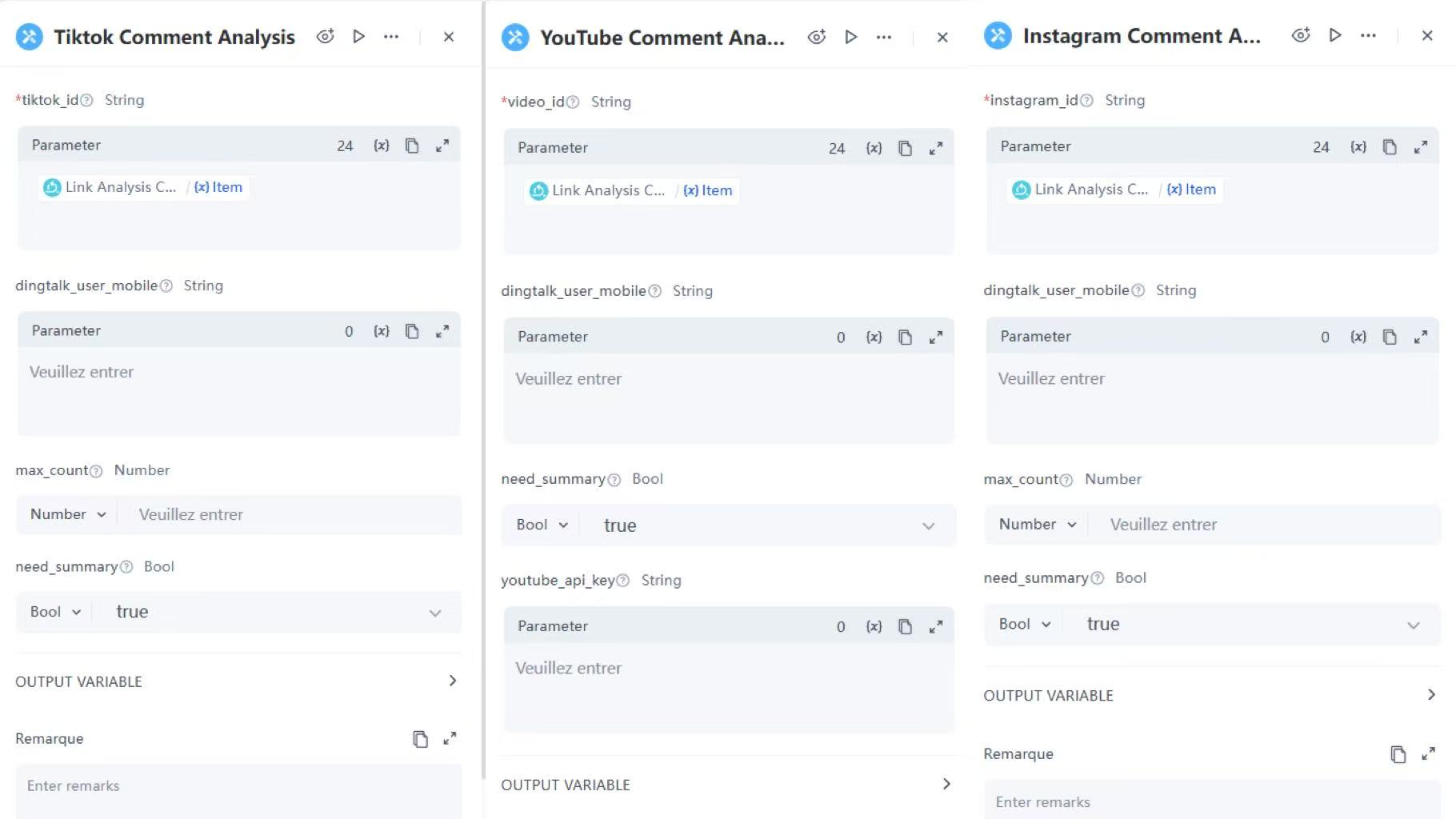
來自不同平台的連結會路由至其各自已發布的服務。例如,包含 "tiktok" 的連結將會導向 TikTok 評論分析服務進行進一步分析。
TikTok 評論分析服務節點範例設定:
- 參數:參考迴圈中的 item
- 需要摘要: 選取 布林值,輸入 true
YouTube 和 Instagram 評論分析工具的設定與 TikTok 相同。
如果使用者的輸入不包含 TikTok、Instagram 或 YouTube 連結,則向使用者傳送提醒訊息。
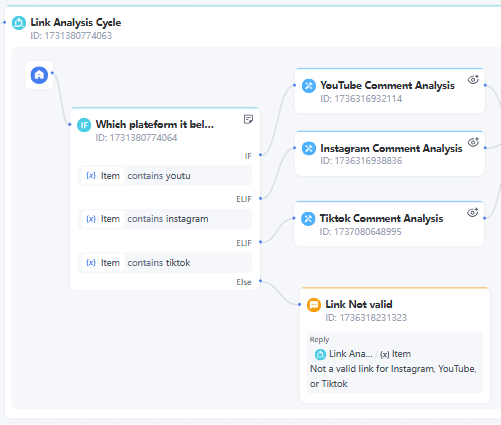
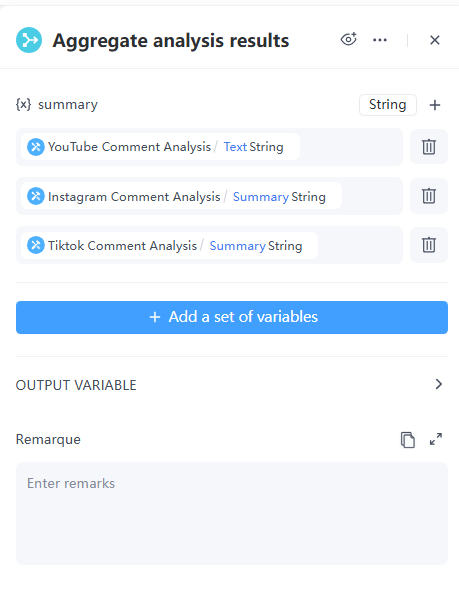
8. 分支聚合節點
現在彙總來自三個平台的分析結果,以取得最終的 summary。
9. 如果/否則節點
在某些情況下,影片可能沒有使用者評論,導致摘要為空。因此,我們需要預期工作流應如何處理這種情況。
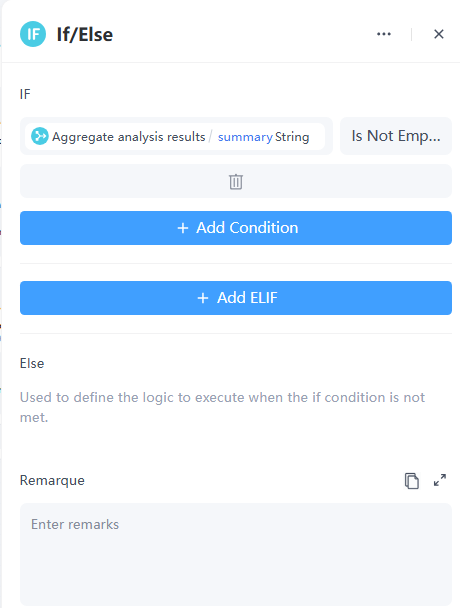
10. 回覆節點
- 當摘要不為空時,自訂回覆範本如下:
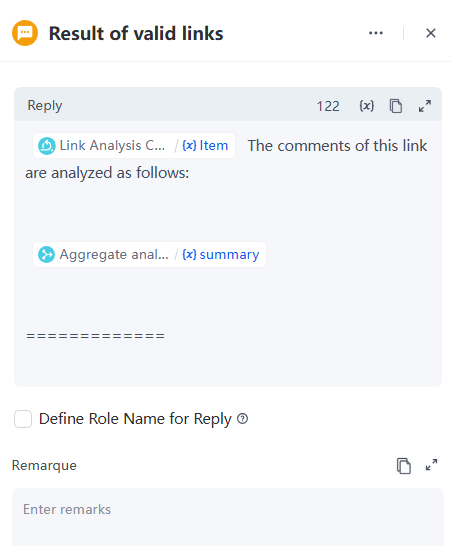

- 發現錯誤或有建議?請告訴我們,當摘要不為空時,自訂回覆範本如下:
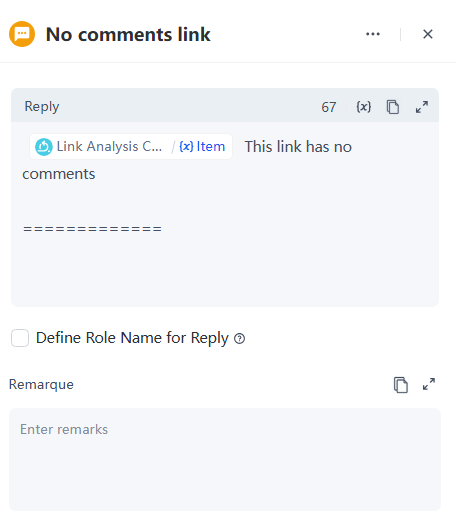

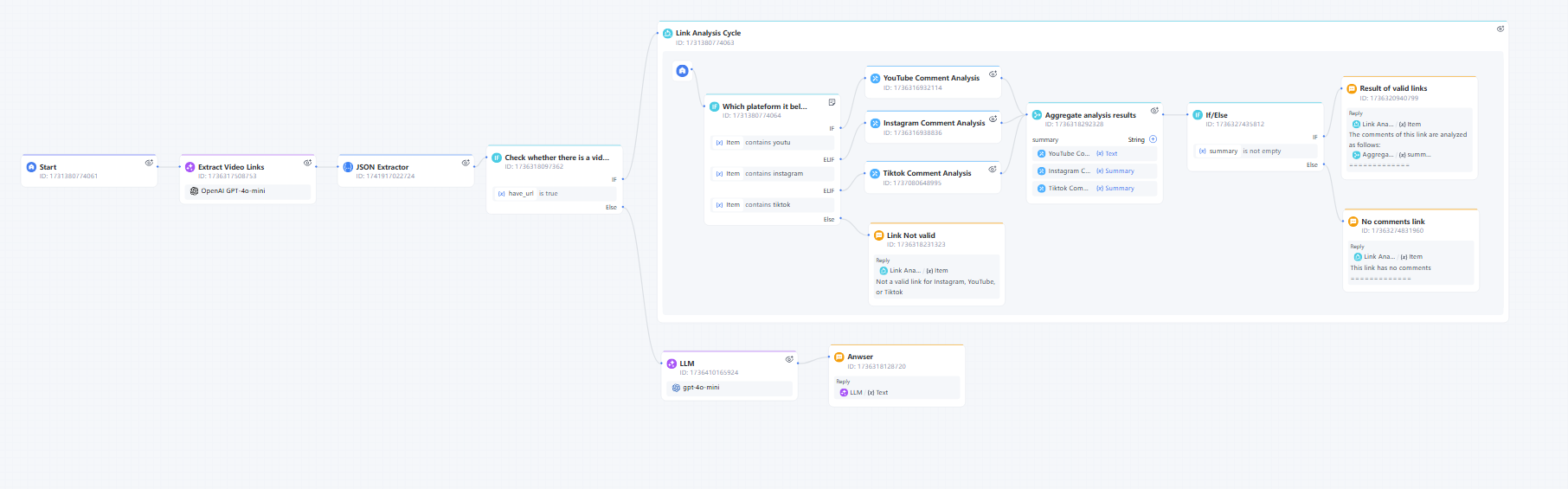
請注意,步驟 6、7、8、9 和 10 涉及在迴圈中處理和分析連結。整個迴圈節點的功能如下:
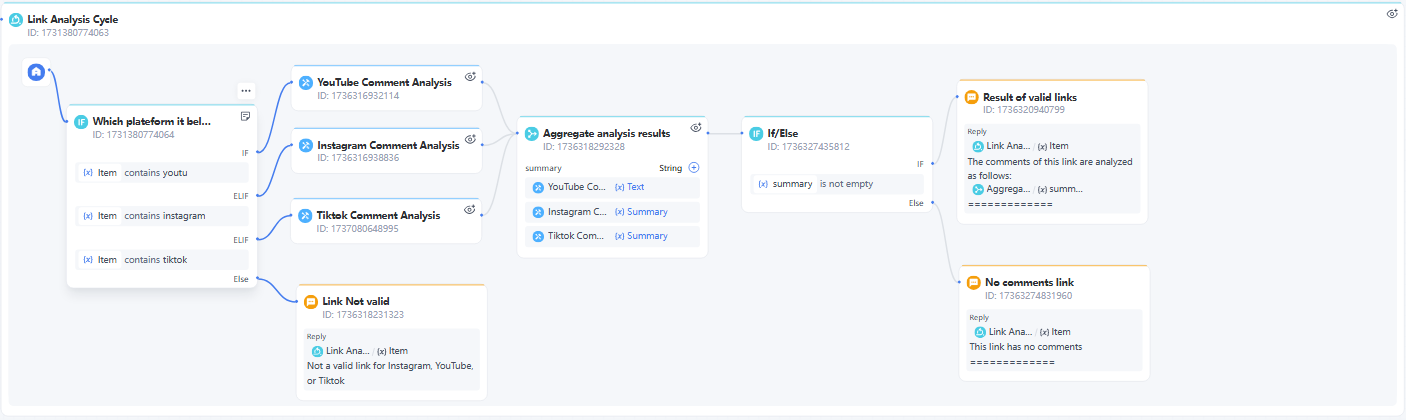
現在我們已經完成了 YouTube、Instagram 和 TikTok 評論分析的互動式流程!讓我們來看看如何偵錯對話工作流。
步驟 3:偵錯工作流
點選「偵錯與預覽」以查看對話式聊天機器人的介面。當您輸入連結時,您可以從下拉式選單中查看每個節點的執行過程。檢閱這些步驟有助於識別問題並最佳化工作流。
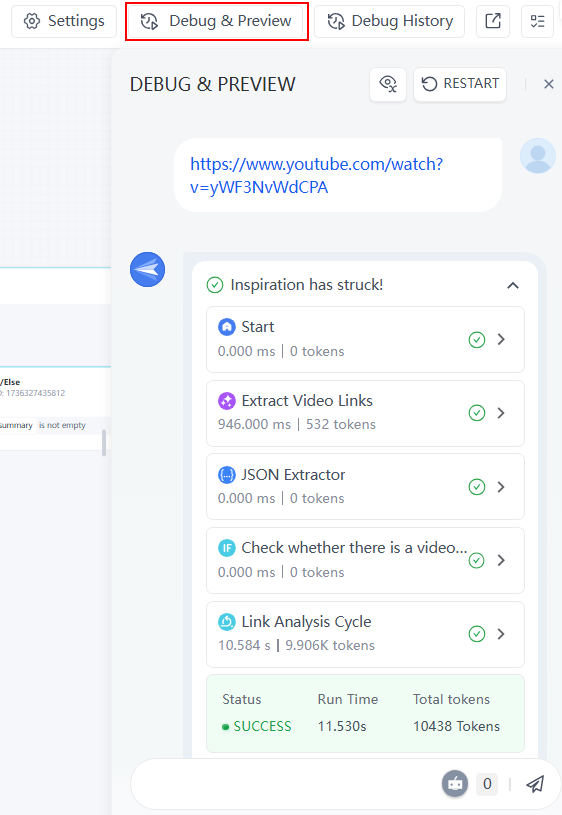
步驟 4:分享聊天機器人
所有問題皆已解決,現在您可以將此對話式聊天機器人分享給他人使用。
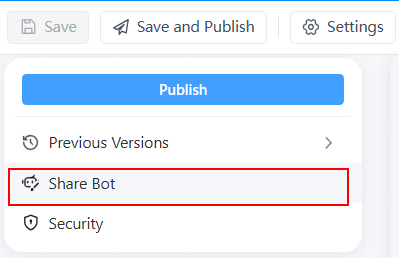
發佈評論