定義:
問題分類器節點利用大型語言模型 (LLM) 的自然語言理解和推理能力來執行語義分析,並對例如使用者查詢或對話內容等文字輸入進行分類。
使用預定義的分類標籤(如「售後服務」、「售前服務」),它生成最符合輸入語義的分類結果。然後將結果傳遞給下游節點,以決定後續的處理流程。
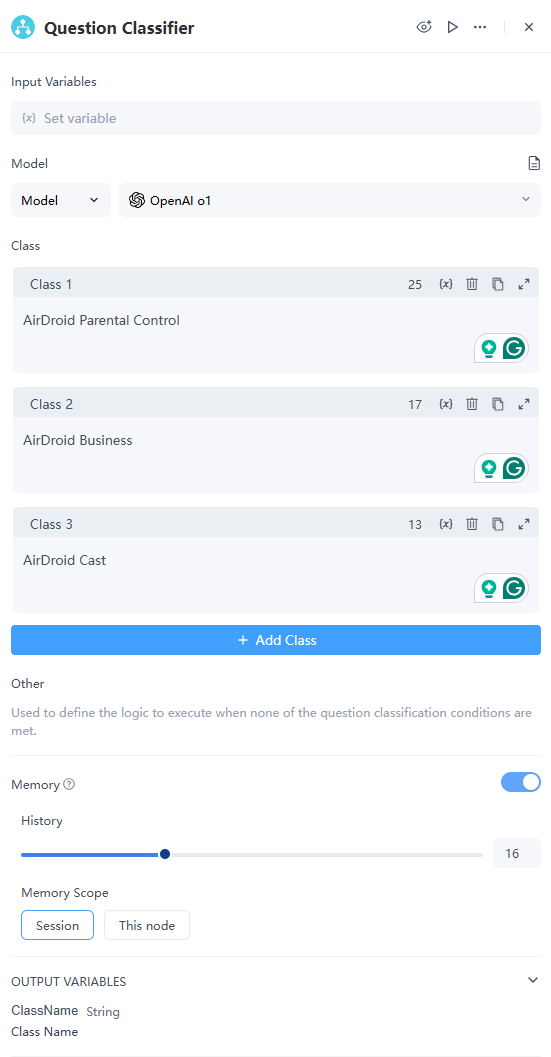
如何配置
輸入變數
此變數表示要分類的內容,並支援檔案輸入。
模型
使用推理模型以獲得最佳結果。由於問題分類器依賴於LLM的語言分類和推理能力,選擇合適的模型可以顯著提高分類準確性。也支援調整模型設定,如「溫度」,以自定義其行為。
分類
您可以為每個分類設定關鍵字,以新增多個分類,使LLM能夠更好地理解分類並將輸入路由到正確的工作流程中。若未符合任何分類條件時,模型會自動執行「其他」分類。
記憶(對話式工作流程)
啟用記憶功能時,分類器會保留對話歷史,以幫助模型對當前對話的上下文進行深入分析。這有助於提升對上下文的理解,並提高互動對話中的回應準確性。
- 歷史記錄:LLM最多可以記住過去的50條使用者消息。您可以設定歷史記錄數量,範圍為1到50。
- 記憶範圍:模型會記錄最後一個使用者提示詞,以追蹤當前會話和節點。若要在目前節點層級啟用記憶功能,請將最後一個使用者提示詞設為記憶。
輸出變數:
模型會回傳一個名為 ClassName 的字串變數,其中包含所選分類的名稱資訊。
簡單案例範例:
此模型非常適合用於客戶服務問題分類。在典型的問答場景中,問題分類器會自動將客戶問題分類,然後引導至正確的知識庫,以提供準確和有幫助的使用者回應。
以下為產品相關客戶服務場景的工作流程範本:
在此範例中,我們設置了三個分類標籤/描述。
- 分類1:AB 售後服務
- 分類2:AB-售前服務
- 分類3:個人產品相關問題
- 若使用者查詢不符合上述任一條件,模型會執行「其他」分類。
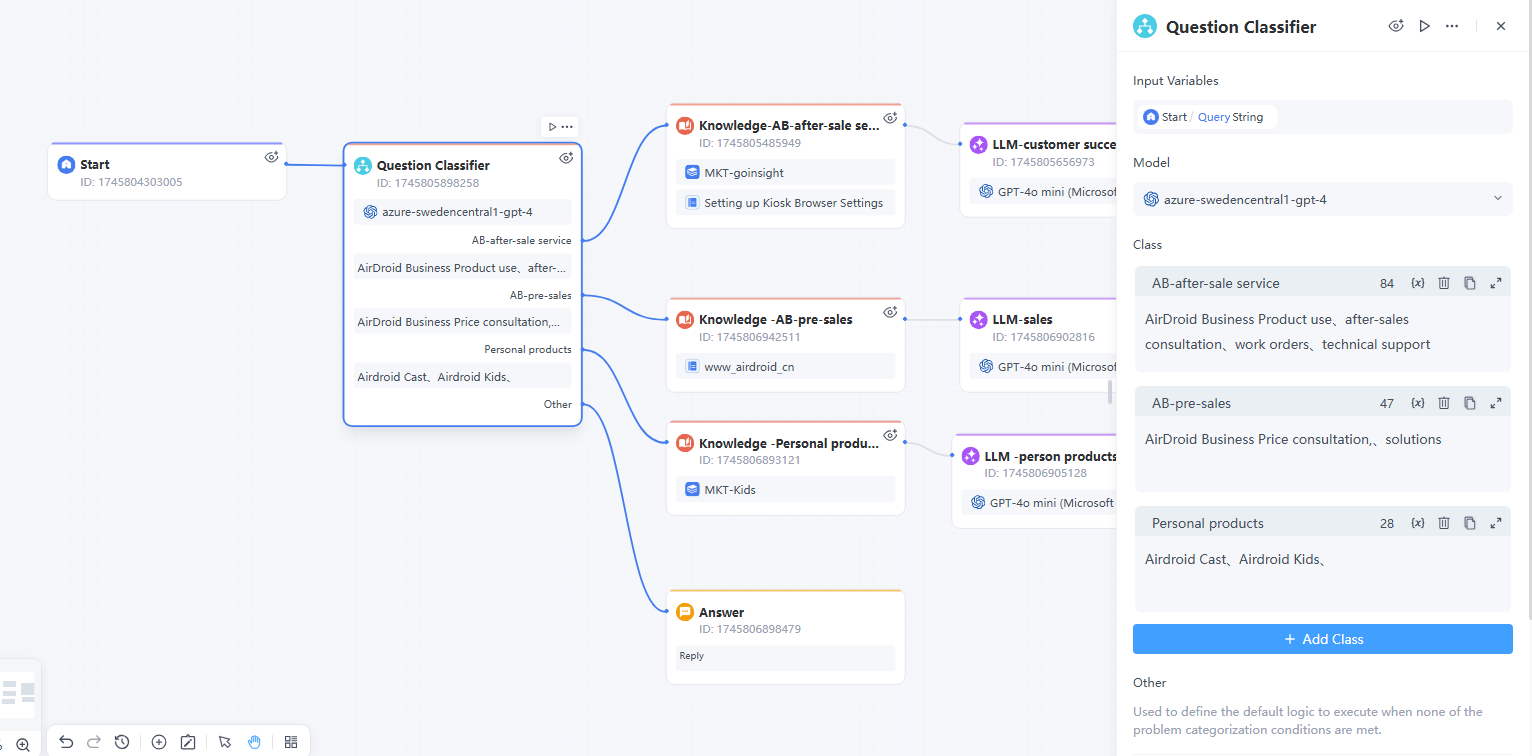
當使用者輸入不同的問題時,問題分類器將根據設置的分類標籤/描述自動完成分類。例如,如果使用者輸入:
- 「AirDroid商務企業版的價格是多少?」→ 歸入「售前」分類。
- 「如何創建和部署Kiosk 配置?」→ 歸入「售後」分類。
- 「如何將AirDroid Cast投放到電視上?」→ 將其分類為「個人產品相關問題」。
- 「今天紐約的天氣如何?」→ 歸入「其他問題」。
注意:
- 輸入變數必須是字串,且不能為空問題。
- 每個分類名稱必須不同。請勿使用重複或無效的名稱。
- 請保持每個分類的描述清晰簡潔,以便分類器做出正確判斷。
發佈評論