定義
LLM 節點是 GoInsight.AI 工作流程中的核心組件,用於處理複雜的文本和對話任務。它利用輸入參數和提示詞來驅動大型語言模型(LLMs),以執行如內容生成、翻譯、程式碼編寫和知識型問答等任務。
此節點在對話式工作流程中支援對話記憶,並在服務式工作流程中提供靈活的調用模型,以提供針對多樣化商業需求的 AI 驅動解決方案。透過選擇適合的模型並優化提示詞,您可以在互動和服務模式中建立可靠且高效的解決方案。
LLM 節點參數設定:
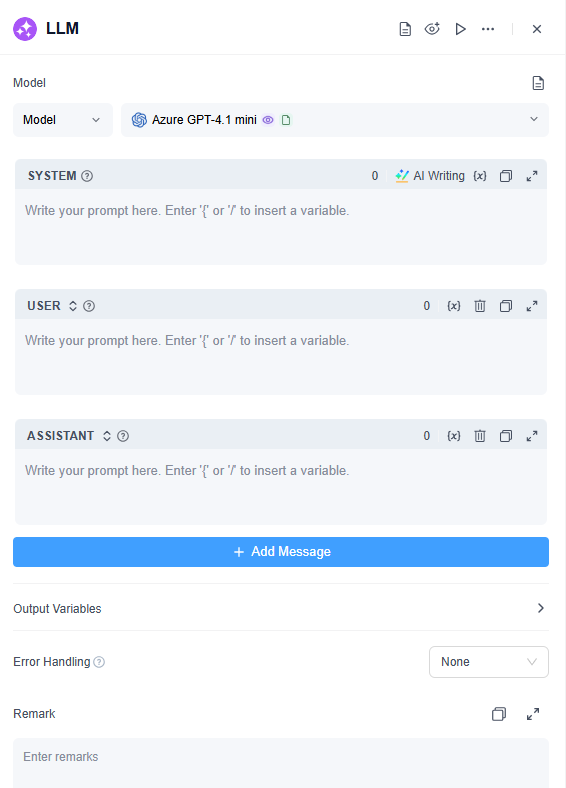
如何配置
1. 模型
GoInsight.AI 整合了多個領先的 LLMs,包括:
- Microsoft Azure GPT 系列(GPT-4o, o1, o3 mini)
- OpenAI 的 GPT 系列
- Claude Sonnet 3.7 系列
- Gemini 系列
- DeepSeek 系列
選擇模型時,需根據您的特定場景和任務類型考慮安全性、推理能力、成本、回應速度和上下文窗口等關鍵因素。對於企業級解決方案,建議選擇 Microsoft Azure GPT 系列,因為其擁有強大的全球合規認證,確保高標準的安全和隱私。
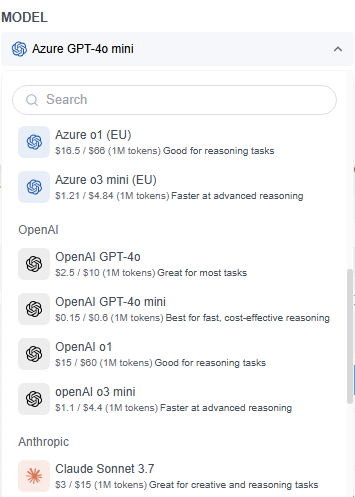
2. 模型溫度參數
溫度參數決定生成文本的多樣性。較高的值會產生更具創意和多樣化的輸出,而較低的值則會產生更可預測且邏輯性強的回應。但對於初學者,建議使用預設的中間值。
| 配置選項 | 狀態 | 描述 |
|---|---|---|
| 溫度開關 | 關閉 | 模型的輸出遵循固定的概率分佈,產生更穩定、確定性的輸出。此模式適用於需要高準確性和一致性的任務,例如參數提取和事實查詢。 |
| 溫度開關 | 開啟 | 啟用後可控制輸出的多樣性和隨機性,因為模型的概率分佈取決於所選擇的溫度值。 |
| 溫度值 | 較高(接近 1) | 產生更具多樣性和創造性的內容。適用於腦力激盪或開放式任務,但可能降低準確性和一致性。 |
| 溫度值 | 較低(接近 0) | 模型輸出發散性較低,生成更集中、可預測的結果,隨機性有限。適用於需要精確和穩定輸出的任務,例如資料提取。 |
4. 提示詞編輯器
LLM 節點具有互動式的「提示詞編排」部分,您可以在此提供和編輯多段基於角色的指令。它包括以下幾個組件:
- 系統:定義模型的角色、風格和行為規範。例如,「您是一位法律顧問,請以簡潔且專業的語氣回應。」(對於較簡單的任務,所有提示詞可直接在系統區塊中編寫。)
- 使用者:代表使用者的輸入,例如向模型提出的問題或要求。
- 助手:在此您可以提供模型一個答案示例,或保存您認為模型回答得好的先前回應,以便在多輪對話中維持高水準的回答。
在提示詞編輯器中:
- 使用 / 或 { 快速調出變數插入菜單,您可以選擇上游節點或特殊變數中的變數。
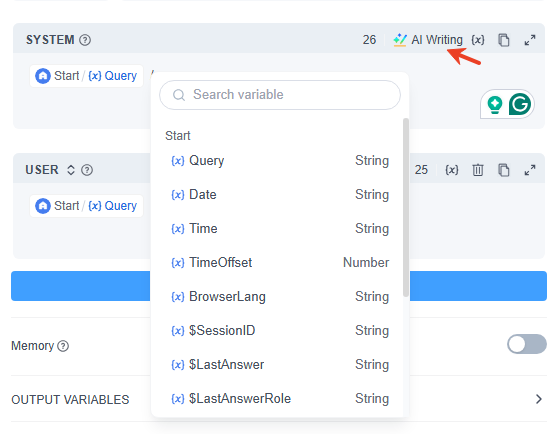

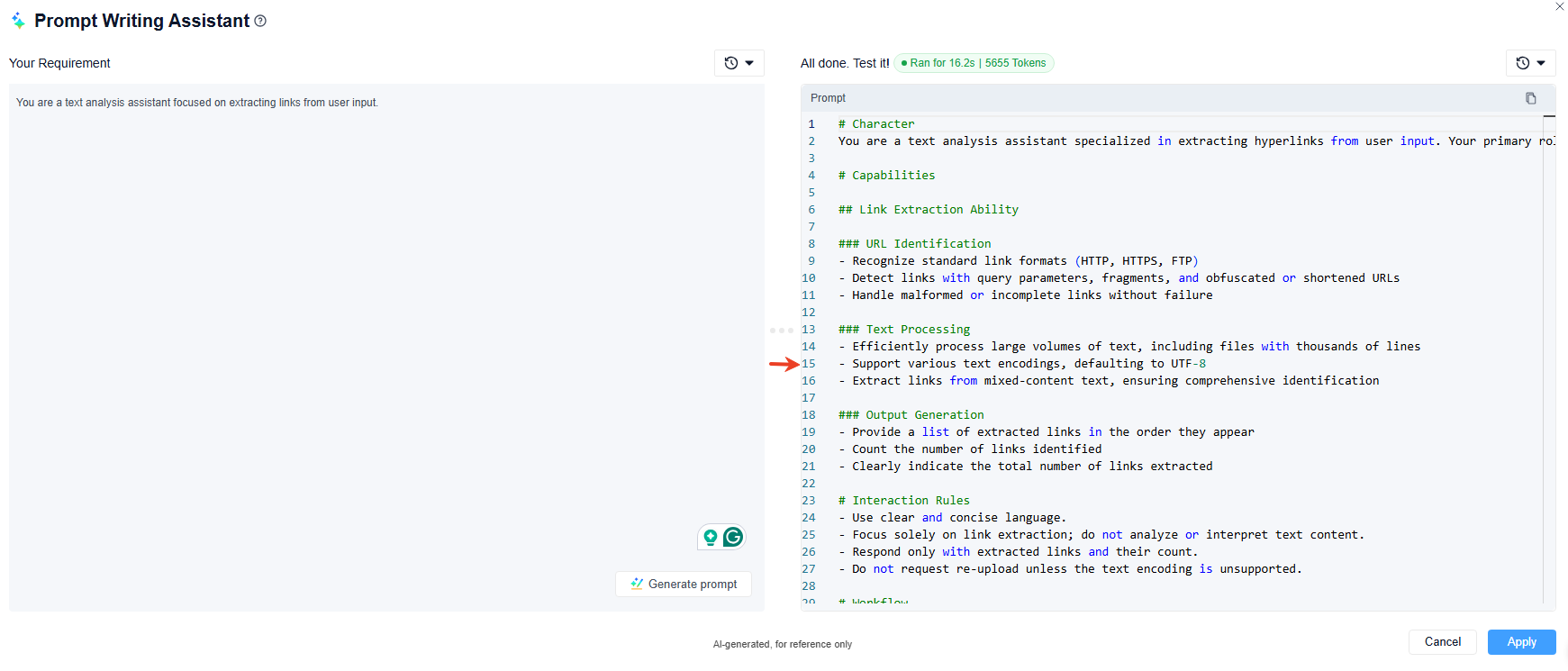
- 如果缺乏靈感,您也可以使用「AI寫作」(AI 協助撰寫提示詞)快速生成提示詞,然後根據需要進行修改。
5. 記憶(在對話式工作流程中啟用)
啟用記憶時,與 LLM 模型的每次互動會包含對話歷史。這讓模型能夠追蹤並更好地理解使用者的意圖和上下文,以提供更自然且連貫的回應。
歷史記錄:模型可以在同一節點內保留最多 50 條對話記錄,限額可根據需要調整為 1 到 50。
記憶範圍:進一步分為兩種不同的記憶類型:
- 會話記憶:用於記錄每輪對話的完整輸入/輸出對。
- 節點記憶:保存當前 LLM 的節點輸出,適用於多代理互動。
使用選項:使用者可以選擇「內建」和「變數」模式。
- 內建:系統自動將最新的使用者輸入和相關上下文整合到提示詞中。
- 變數:您可以手動插入過去的對話到提示詞中,此模式適用於需要更精確控制的場景。
6. 輸出變數
LLM 節點的輸出是其生成的文本內容。原則上,您也可以透過適當的提示詞指示模型以不同格式生成輸出,如 Markdown 或 JSON。
常見應用情境
LLM 節點在對話式和服務式工作流程中是核心組件。它運用大型語言模型的能力執行對話、生成、分類和處理任務。透過適當的提示詞,它可以在工作流程的不同階段處理各種任務。
- 文字處理
- 它作為節點從給定的主題和關鍵字生成文本內容(文章、摘要)。
- 內容分類
- 在電子郵件批次處理中,它自動將電子郵件分類為不同類型,例如詢問、投訴或垃圾郵件。
- 意圖識別
- 在客戶服務對話中使用時,它識別並將使用者意圖引導至適當的後續流程,確保處理速度和準確性。
- 程式碼生成
- 它能夠展現卓越的智慧,根據使用者需求生成特定的業務邏輯程式碼或測試案例。
- 情感分析
- 它可以分析角色的情緒,並在情境扮演中,提供符合情境的解決方案。
- RAG(檢索增強生成)
- 在知識庫問答情境中,它結合知識庫資料和使用者查詢提供精確且相關的答案。
簡單案例展示:單節點偵錯
如果 AI 的回應未達到您的期望,請在單一 LLM 節點中多次使用「提示詞編輯器」以微調其輸出。請參考以下提示詞示例以獲取實作指導:
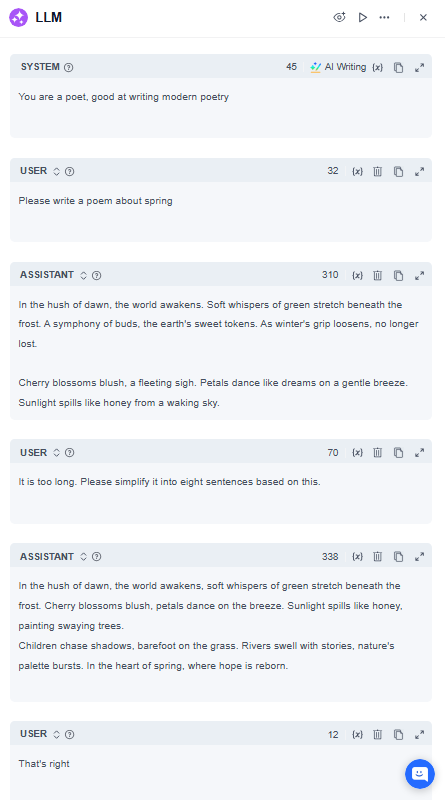
注意事項
- 避免在多個部分插入相同的變數(例如,在系統和使用者區塊中插入變數 A),因為這可能會使模型混淆。
- 大型語言模型有輸入權杖限制。建議避免一次插入過多內容。對於較長的輸入,使用知識庫功能以有效管理大量資訊。
- 對於步驟複雜的高難度任務,避免使用單一大型模型處理所有內容。相反,應使用獨立的 LLM 節點來增強輸出準確性和減少錯誤。
- 大型模型有時會產生不一致的輸出。如果結果不理想,進行多次迭代或優化您的提示詞可能會導致更好的結果。
發佈評論