定义:
此自然语义变量提取器节点利用“大型语言模型 (LLM)”分析和解释自然语言输入,以结构化的格式提取用户定义的变量参数。
如何配置
模型:
从模型下拉菜单中选择您想要使用的**大型语言模型**。您可以调整语言模型的“温度”,它决定了模型的**随机性或发散程度**。较高的值会导致更具创造性和多样化的响应,而较低的值会**产生**更集中和更精确的输出。
详细说明如下:
| 配置选项 | 状态 | 描述 |
|---|---|---|
| 温度开关 | 关闭 | 模型的输出遵循固定的概率分布,从而产生更稳定和确定性的输出。适合需要高精度和一致性的任务,如参数提取和事实查询。 |
| 温度开关 | 开启 | 启用对输出多样性和随机性的控制,因为模型的概率分布取决于所选的温度值。 |
| 温度值 | 较高(接近1) | 产生更具多样性和创造性的内容,**且变化性更大**。适合用于头脑风暴或开放式任务,但可能降低准确性和一致性。 |
| 温度值 | 较低(接近0) | **模型的输出发散性更小**,生成更集中和可预测的结果,随机性有限。适合需要精确和稳定输出的任务,如数据提取。 |
输入变量:
这指的是自然语言数据输入的来源,可以是:
- 工作流中开始节点的默认{x}Query
- 前一个节点的输出变量
提取参数:
点击“+”可以添加和配置“提取参数”。每个参数需要填写3个变量:“提取提示词”、“名称”和“类型”。
- 提取提示词:提供要提取内容的清晰描述,并给出特定名称(例如,提取电话号码)。
- 名称:为提取的数据定义一个自定义名称或标识符(例如,customer-phone)。
- 类型:指定输出变量的数据类型(例如,String,Array[String])。
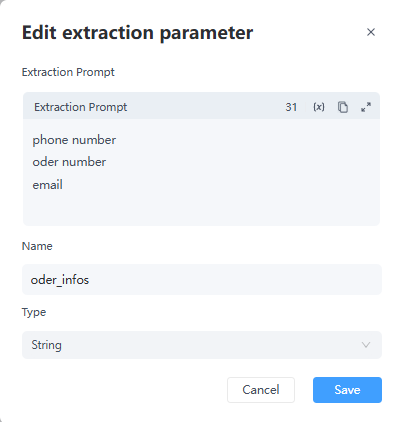
输入文本示例为:“我的电话号码是123456,电子邮件是xxxxxx@airdroid.com,订单号是987654。”这里:
| 类型 | 输出 |
|---|---|
| String | “123456,xxxxxx@airdroid.com,987654” |
| Array[String] | [ "123456", "xxxxxx@airdroid.com", "987654" ] |
示例展示
建议提供额外的提示词,以帮助模型更准确和精确地提取复杂的变量。
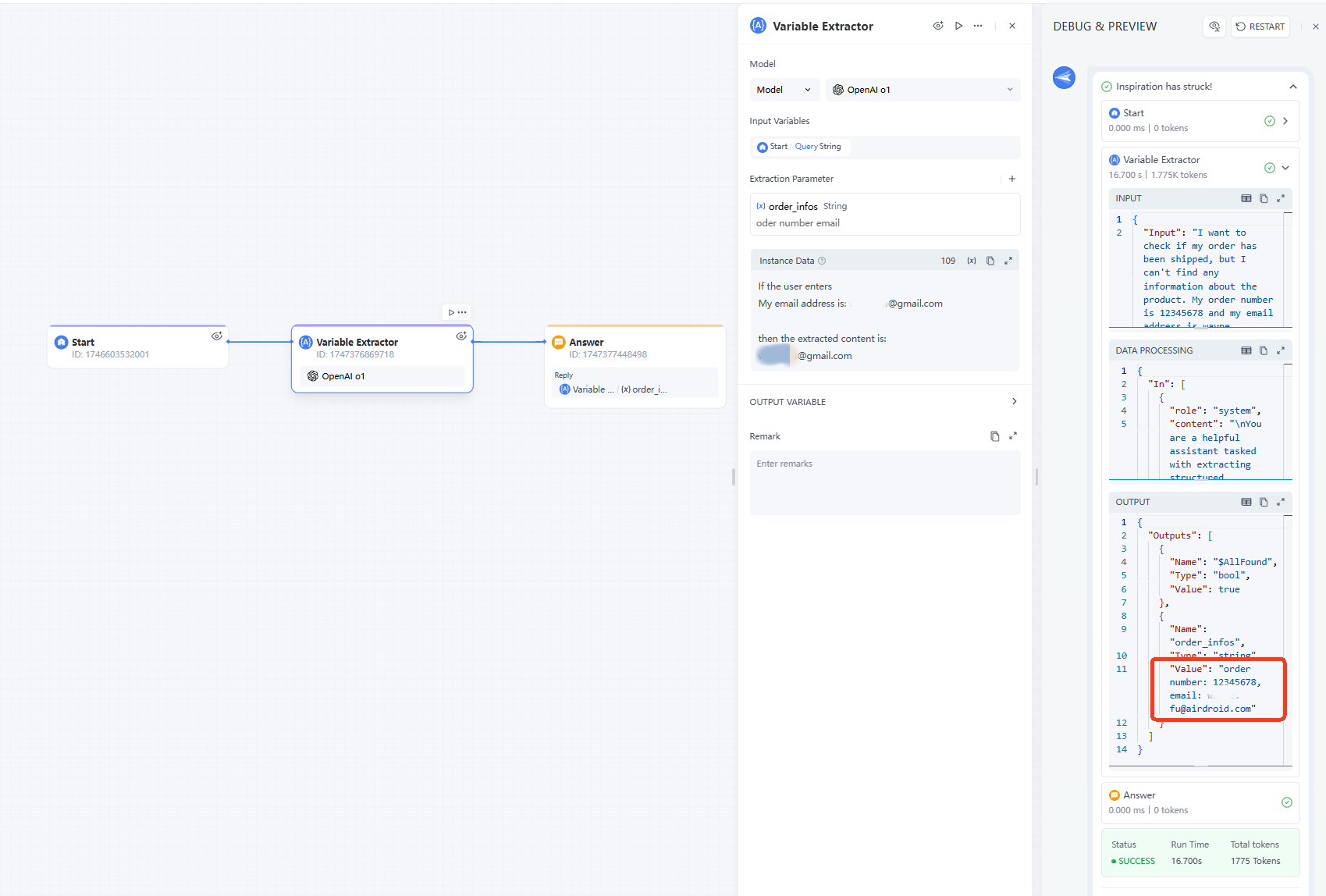
简单案例 - 完整示例
使用案例(目标):从用户输入中提取重要或相关信息。
开始节点:
自然语义变量提取器:设置提取参数为:
- 提取提示词:订单号,电子邮件
- 名称:order_infos
- 类型:String
用户输入示例:“我想检查我的订单是否已发货,但我找不到有关产品的任何信息。我的订单号是12345678,我的电子邮件是xxxxxx@airdroid.com。请帮我找一下。”
回复输出:
- "名称":"order_infos"
- "类型":"String"
- "值":"12345678, xxxxxx@airdroid.com"
发表评论.