让我们一起创建第一个工作流!我们将从一个服务流的示例开始。
假设您有一个新想法。例如,您希望AI帮助分析并汇总YouTube视频下的评论。实现这个想法的过程很简单:

使用以下节点将此过程转换为GoInsight.AI的工作流:开始节点 → HTTP请求节点 → 代码节点 → LLM节点 → 结束节点。以下是创建此工作流的详细信息。
如何创建YouTube评论分析服务流
步骤1:创建服务流
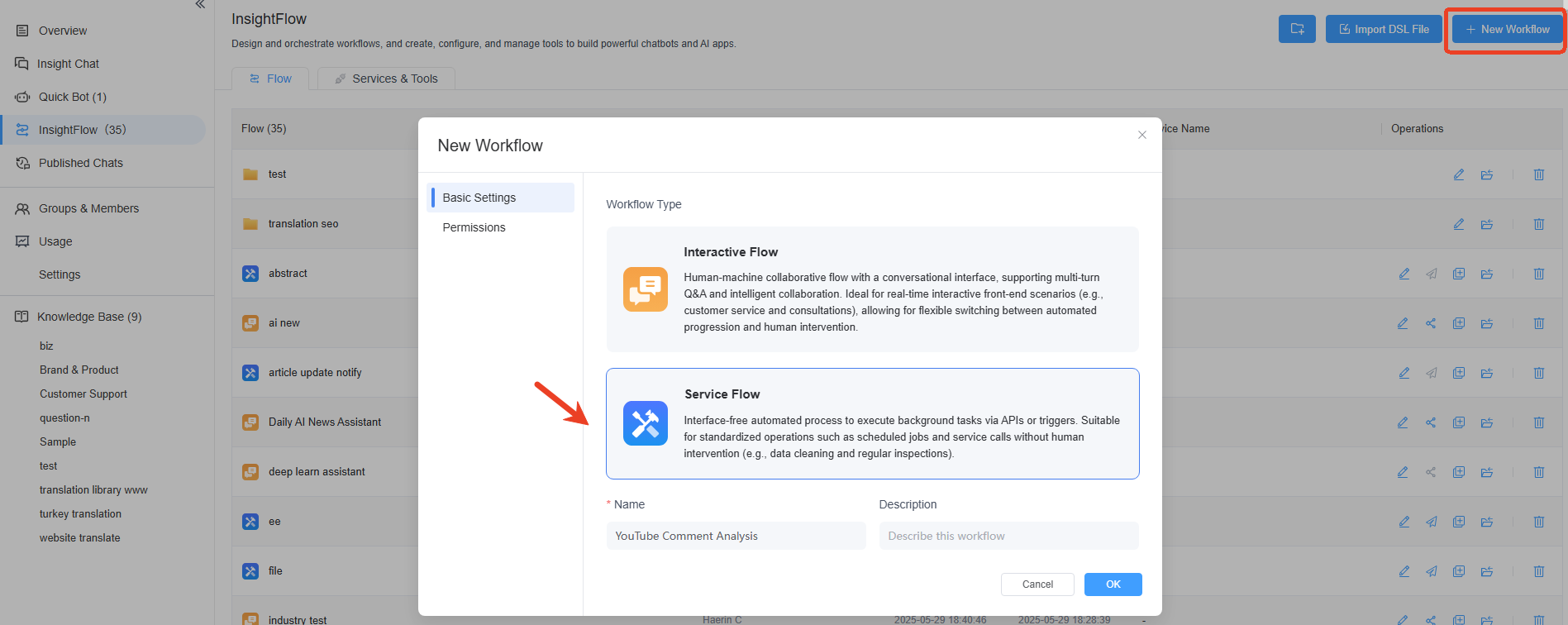
点击右上角的“新建工作流”,选择“服务流”,并填写工作流的名称、描述或设置权限。
步骤2:配置工作流节点
1. 开始节点
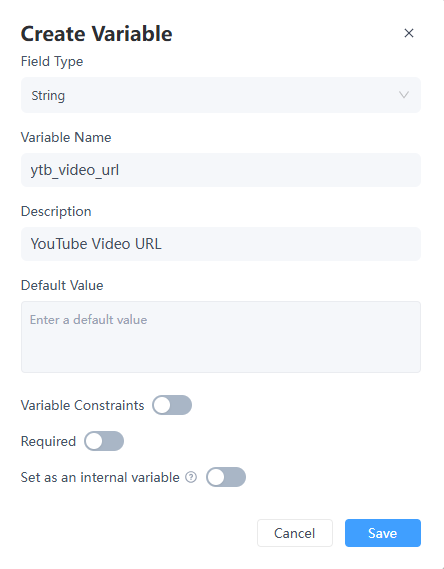
在开始节点中,由于用户输入的链接每次可能不同,创建一个名为ytb_video_url的自定义变量,并将变量类型设置为String。
2. 代码节点
要从YouTube视频中获取评论数据,你需要一个能够检索评论的API。通常,你可以使用Google提供的官方API。根据API文档,你需要从用户输入的ytb_video_url中提取视频ID。
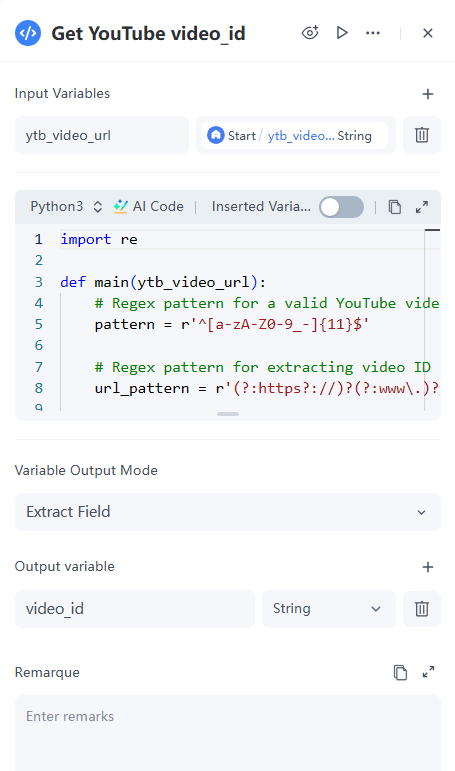
配置细节:
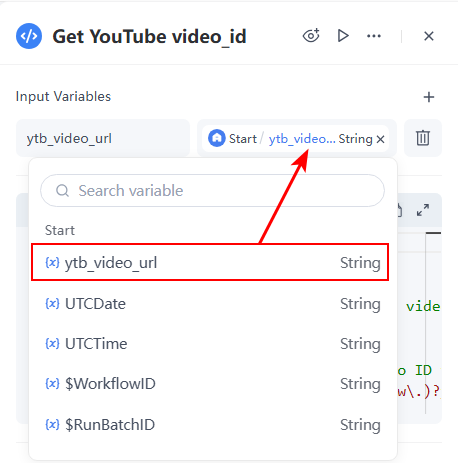
- 输入: 从参数的下拉列表中选择ytb_video_url,该变量已在开始节点中定义。变量将自动命名为ytb_video_url。
- 代码: 下面提供了参考代码。
import re
def main(ytb_video_url):
# Regex pattern for a valid YouTube video ID
pattern = r'^[a-zA-Z0-9_-]{11}$'
# Regex pattern for extracting video ID from a YouTube URL
url_pattern = r'(?:https?://)?(?:www\.)?youtube\.com/(?:shorts/|watch\?v=)([a-zA-Z0-9_-]{11})'
# Check if the input is a valid video ID
if re.match(pattern, ytb_video_url):
return {'video_id': ytb_video_url}
else:
# Extract video ID from URL
match = re.search(url_pattern, ytb_video_url)
if match:
return {'video_id': match.group(1)}
# Default return if no valid ID is found
return {'video_id': ''}3. HTTP请求节点
选择合适的API是创建工作流时的一个重大挑战。对于提取YouTube信息,你可以使用Google提供的官方API。首先,你需要注册一个开发者账号并获取一个唯一的API密钥:https://console.cloud.google.com/projectselector2/apis/dashboard
接下来,参考Google YouTube评论API的官方文档来配置HTTP请求节点:https://developers.google.com/youtube/v3/docs/comments/list
配置细节:
- HTTP请求方法:'GET:https://www.googleapis.com/youtube/v3/comments'
- 请求头:'Referer: https://www.xxx.com' (根据API注册时使用的网站域名填写)
- 请求参数:
- part:设置为'snippet'
- videoId: 使用从代码节点获得的video_id
- key:输入您获得的API密钥
- maxResults:可以设置为20到100,此处设置为100,表示最大获取结果数为100。
- textFormat:设置为'plainText'
- 请求体: 默认值是'None'
- 超时时间: 默认值是'30'
- 输出参数:
- 状态码: 返回状态代码,通常'StatusCode=200'表示HTTP请求结果成功。
- 响应头: 返回请求头信息
- 响应体: 返回请求正文内容
输出:如API文档所示,执行HTTP请求后,服务器返回的响应体结果如下。我们需要的评论信息位于items字段下。
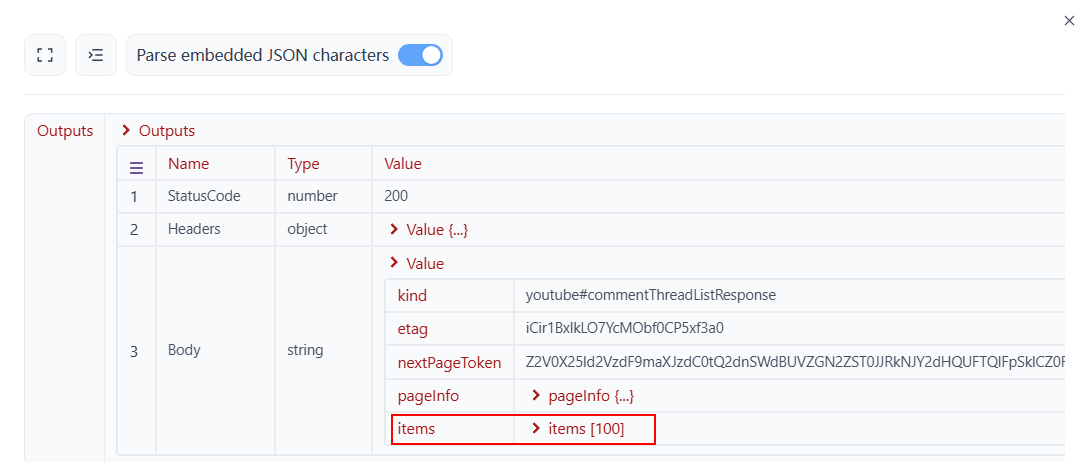
4. 代码节点
经过观察,我们发现items中包含了大量不必要的信息。为了使LLM处理更简洁高效,我们应直接提取相关的评论字段,避免传输不必要的信息。
- 输入: 将变量命名为arg1以引用从HTTP请求节点获得的响应体。
- 代码:
import json
def main(arg1):
response = {'comments': ''}
data = json.loads(arg1)
# Extract comments information
comments = data.get('items', [])
for item in comments:
# Extract required fields from each comment
snippet = item.get('snippet', {}).get('topLevelComment', {}).get('snippet', {})
author = snippet.get('authorDisplayName', '')
published_at = snippet.get('publishedAt', '')
text = snippet.get('textDisplay', '')
# Extract like count and total reply count
like_count = snippet.get('likeCount', 0) # Default is 0
total_reply_count = snippet.get('totalReplyCount', 0) # Default is 0
# Concatenate information
comment_info = f"{author} on {published_at} commented (Likes: {like_count} | Replies: {total_reply_count}): \n{text}"
response['comments'] += comment_info + "\n\n-------------------------------\n\n"
# Return result dictionary with consistent keys
return response
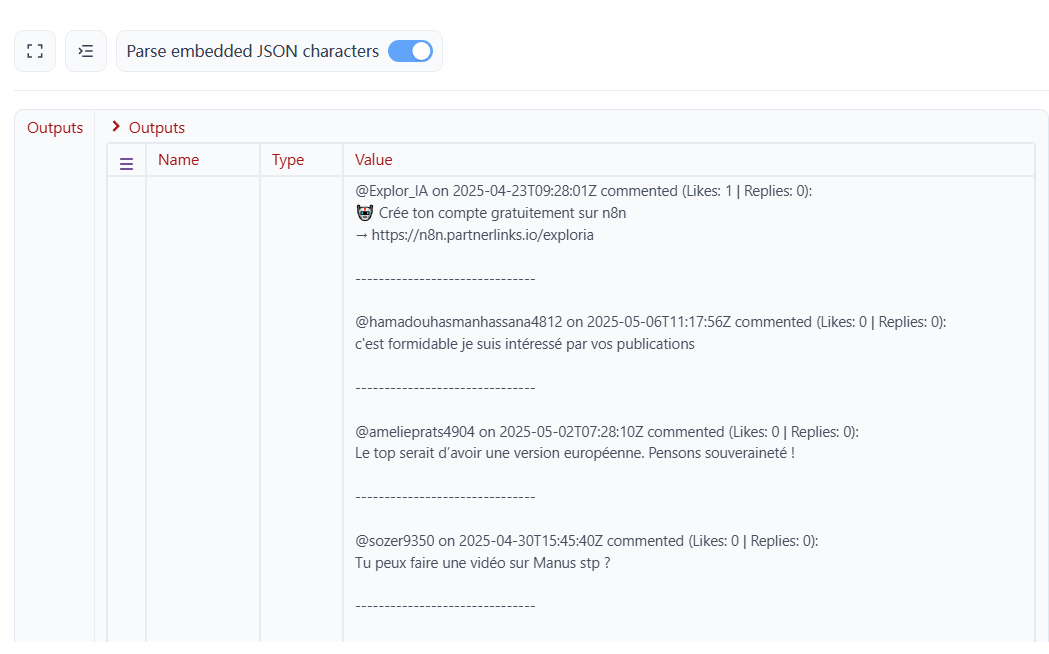
执行代码后,我们成功提取了详细的评论内容。
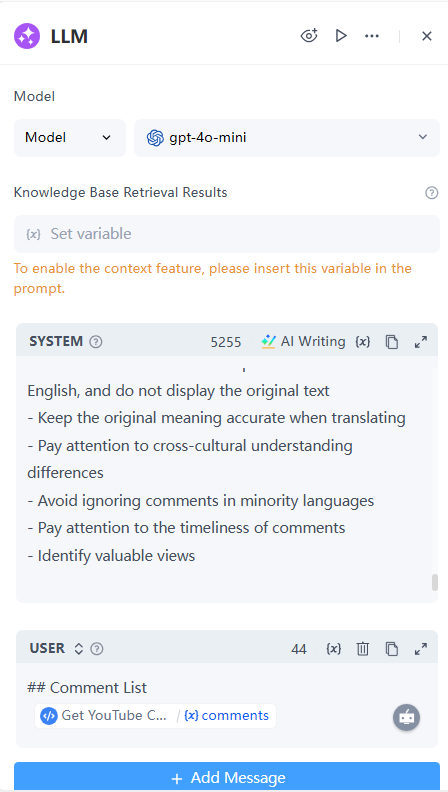
5. LLM节点
接下来,我们利用LLM的语义理解能力来分析检索到的评论。
配置细节:
- 模型: 选择gpt-4o-mini
- 知识库检索结果: 不适用,留空
- 系统:
## 1. 角色设定 您是一名专业的视频内容分析师,擅长从评论中提取有价值的信息,并发现关键问题和见解。请将所有语言的评论分析结果以英文呈现,以便用户理解全球观众的反馈。您的输出不应包含在代码块(```)中。 ## 2. 分析框架 所有评论都应翻译成英文并显示其译文,而非原文。 评论翻译成英文后,请从以下维度进行分析: ### 2.1 评论概述 - 评论总数和语言分布 - 主要评论语言及其比例 - 评论时间分布特征 - 高赞评论的语言偏好分析 ### 2.2 评论内容分类 - 技术讨论(代码、工具、框架等) - 经验分享(个人经验、建议等) - 问题咨询(疑问、帮助等) - 情感表达(赞美、抱怨等) - 其他互动(如玩梗、社交等) ### 2.3 核心反馈 - 最常提到的意见或问题 - 不同语言用户的共同关注点 - 各语言群体的独特观点 - 重要的建设性建议 ### 2.4 互动特征 - 评论区讨论的热门话题 - 跨语言的交流与互动 - 有价值的补充信息 - 特殊的用户贡献 ## 3. 输出结构 请按以下格式输出分析结果: ``` # 评论分析摘要 ## 视频标题:[视频标题] ## 评论数据概述 - 评论总数:[数量] - 语言分布:[主要语言和比例] - 时间分布:[评论时间特征] - 互动情况:[点赞、回复特征] ## 评论内容详细总结 ### 英文评论的主要内容 1. 高赞评论(按点赞数排序,至少10条) - [点赞数] "(英文翻译)原始评论" - [评论者反映的具体问题/观点] 2. 重要讨论话题(按讨论热度排序) - 话题1:[话题描述] * "(英文翻译)评论片段1" * "(英文翻译)评论片段2" * "(英文翻译)评论片段3" * "(英文翻译)评论片段4" * "(英文翻译)评论片段5" * [相关讨论点] - 话题2:[话题描述] … - 话题3:[话题描述] … - 话题4:[话题描述] - … - … - … 3. 有价值的补充信息 - [用户分享的相关资源、链接、经验等] - [具体的技术建议或解决方案] ### 英文评论的主要内容 1. 高赞评论(按点赞数排序,至少5条) - [(英文翻译)原始评论及其核心思想] - [提出的具体问题或建议] 2. 重要讨论话题 - [按话题分类的具体讨论内容] - [用户之间的互动讨论] 3. 独特的本地化视角 - [用户的特定视角或需求] - [与本地化相关的建议] ### 其他语言评论的主要内容 [按语言分类,每种语言还包括: - 高赞评论的英文翻译 - 重要讨论话题 - 独特的视角或建议] ## 评论互动分析 1. 跨语言讨论 - [不同语言用户之间的互动] - [共同关注的话题] - [观点的差异和共识] 2. 问答互动 - [重要问题及其答案] - [社区互助的典型案例] - [尚未解决的关键问题] 3. 有争议的话题 - [主要争议点] - [各方观点陈述] - [讨论趋势] 4. 负面评论 - [主要负面评论点] * "(英文翻译)负面评论片段1" * "(英文翻译)负面评论片段2" * "(英文翻译)负面评论片段3" * … ## 核心发现 [基于详细评论分析的3-5个最重要发现] ## 分类反馈 - 技术相关:[技术讨论点] - 用户体验:[用户体验反馈] - 问题建议:[主要问题和建议] - 情感互动:[用户情感倾向] ## 重要讨论 [2-3个值得关注的跨语言讨论话题] ## 行动建议 [基于全球用户反馈的具体建议] ``` ## 4. 分析原则 - 根据视频标题辅助理解用户评论的含义 - 确保对不同语言的评论给予关注 - 识别跨语言的共同观点 - 保持对文化差异的敏感性 - 从英文视角提供解释 - 关注建设性反馈 ## 5. 注意事项 - 确保所有评论输出均已翻译成英文,不显示原文 - 翻译时需保持原意准确 - 关注跨文化理解差异 - 避免忽略少数语言的评论 - 关注评论的时效性 - 识别有价值的观点
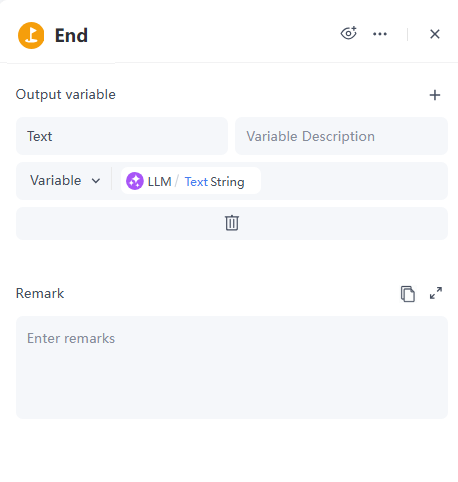
6. 结束节点
输出:将变量命名为Text,引用LLM节点输出的内容。
仅需几个简单步骤,一个YouTube评论分析服务流就完成了!接下来,让我们进行工作流调试。
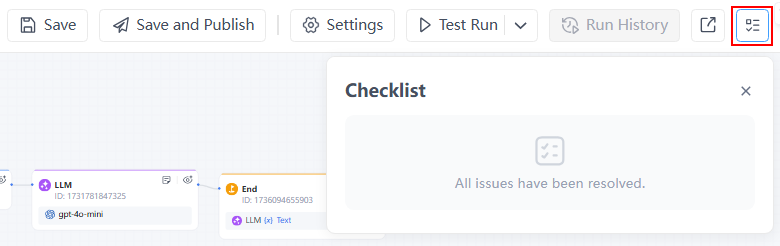
步骤3:调试工作流
- 检查清单,确保所有问题已解决。
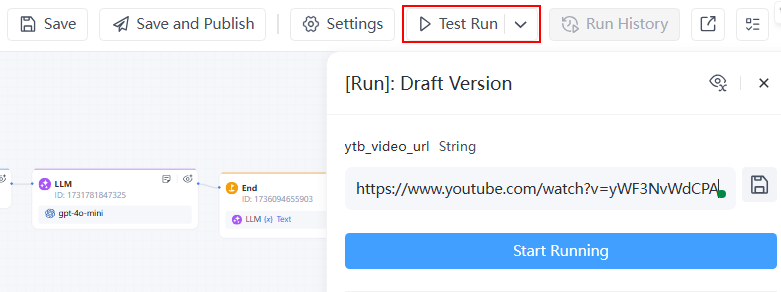
- 点击测试运行,模拟用户输入YouTube视频链接,例如:https://www.youtube.com/watch?v=yWF3NvWdCPA
- 检查工作流结果。你可以点击查看工作流中每个节点的执行和输出,并在必要时进行优化。
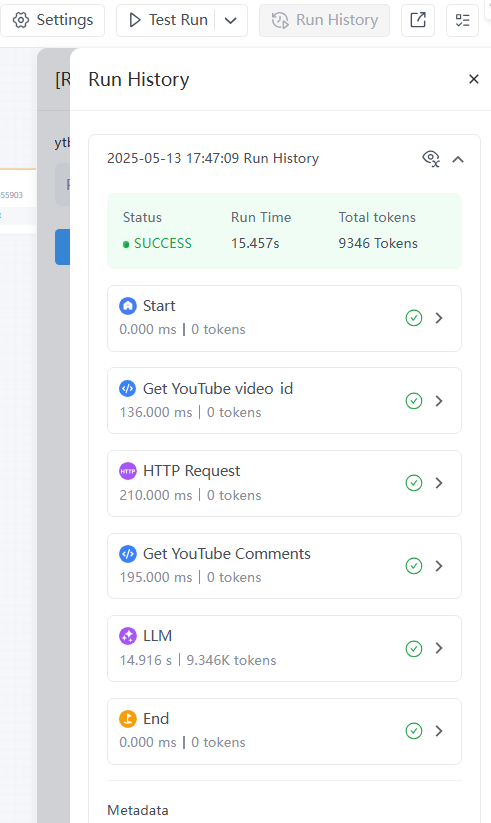
步骤4:发布工作流
一旦工作流完成,我们可以将其作为工具发布,以便在未来的工作流中轻松调用。
参考此教程将服务流作为工具发布:https://www.goinsight.ai/tutorials/publishing-a-service-flow/
使用相同的方法,我们还可以尝试从其他社交媒体平台(如TikTok和Instagram)检索和分析用户评论。
如何创建YouTube/Instagram/TikTok评论分析的互动流
经过一段时间的调试和努力,我们完成了三个服务流:YouTube评论分析、TikTok评论分析和Instagram评论分析。它们的共同特点是,通过输入视频链接,你可以检索和分析视频下的用户评论。现在,让我们考虑如何使这些工作流一起工作,以便于其他同事使用。

想象一下用户将如何使用此工作流。首先,他们输入的链接可能来自YouTube、TikTok或Instagram,也可能同时输入所有三个平台的链接。理想情况下,我们应该能够将不同的链接路由到相应的工作流。
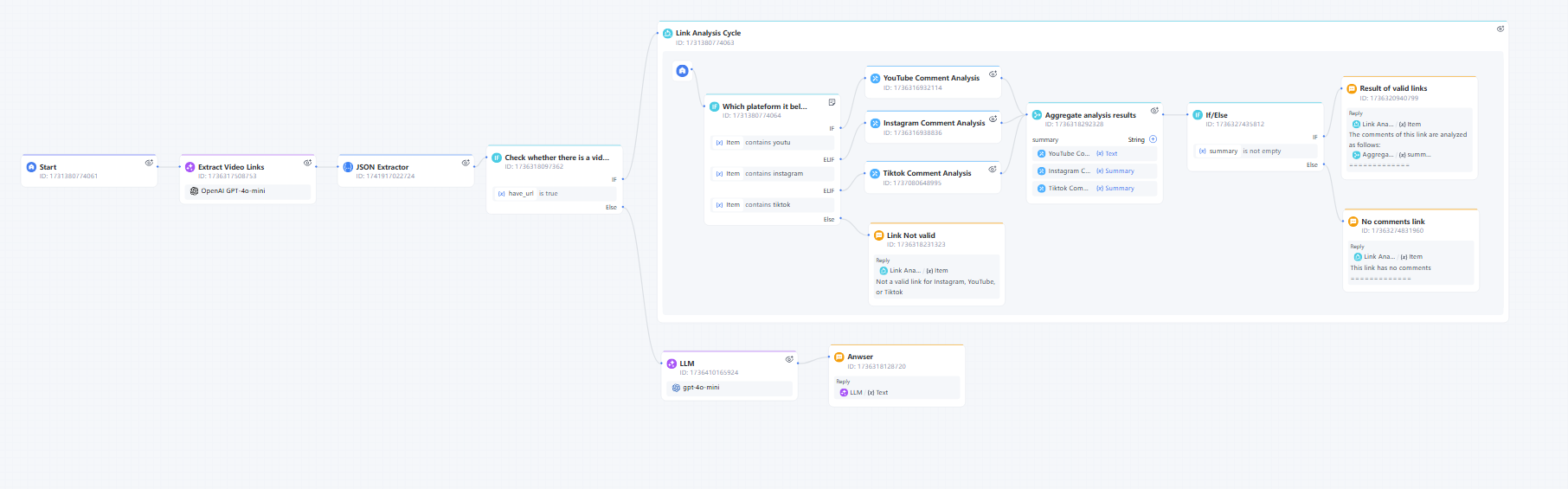
此时,互动流展示了其便利性。用户无需登录后台,只需在聊天框中发送链接即可直接与聊天机器人交流。聊天机器人的功能如下:
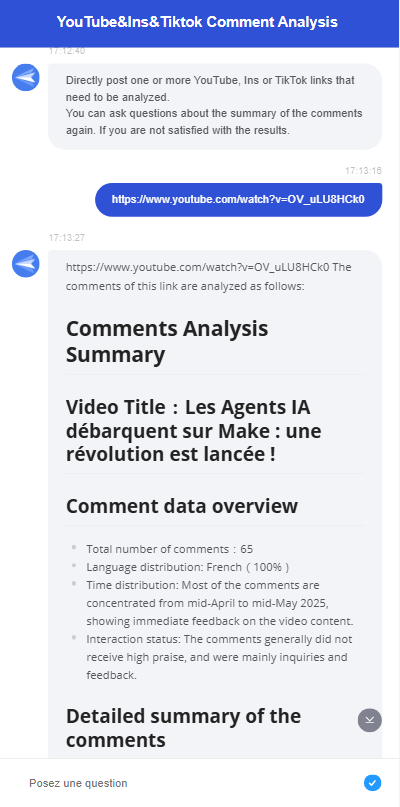
让我们逐步了解如何创建YouTube、Instagram和TikTok评论分析的互动流!
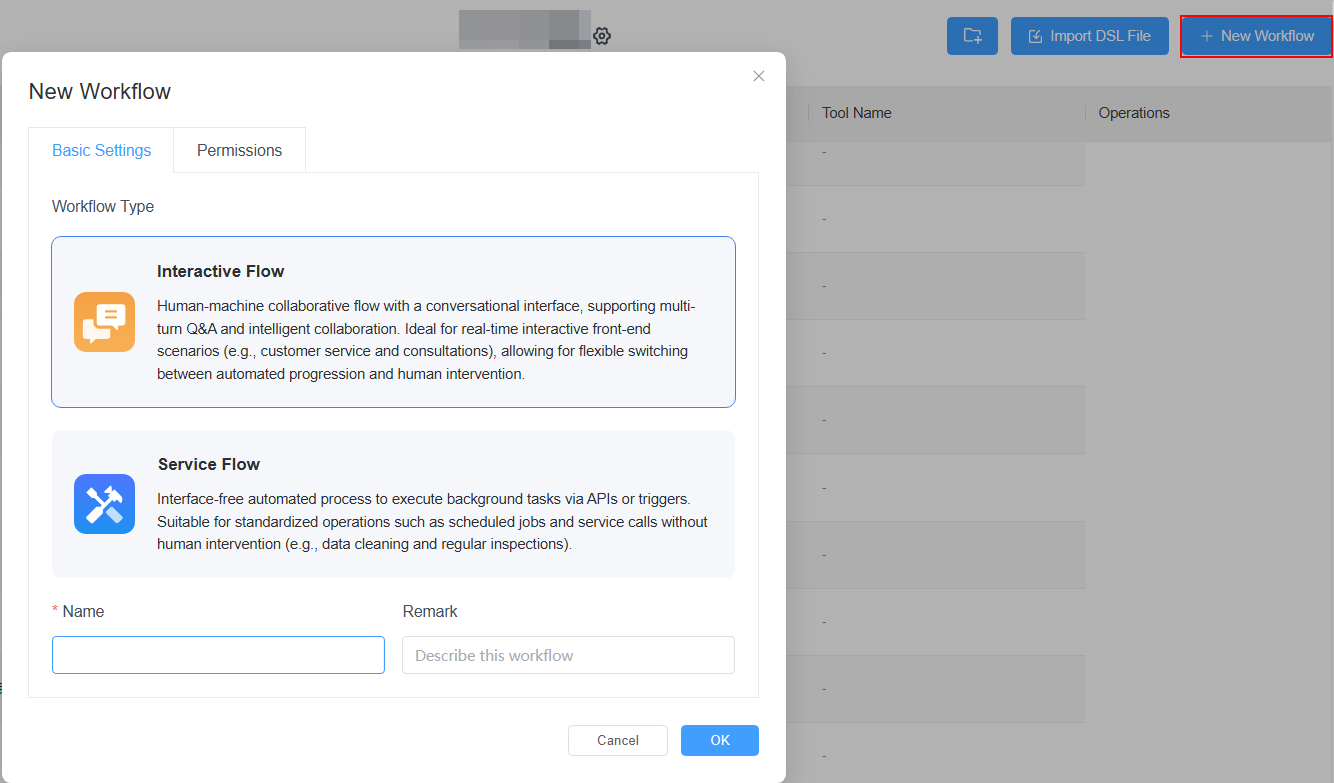
步骤1:创建互动流
点击右上角的“新建工作流”,选择“互动流”,并填写工作流的名称、描述或设置权限。
新创建的互动流将有三个默认节点:开始 → LLM → 回复。
步骤2:配置工作流节点
1. 开始节点
互动流的界面类似于聊天机器人,因此开始节点已经有一个默认的用户输入参数,称为Query,无需自定义。
2. LLM节点
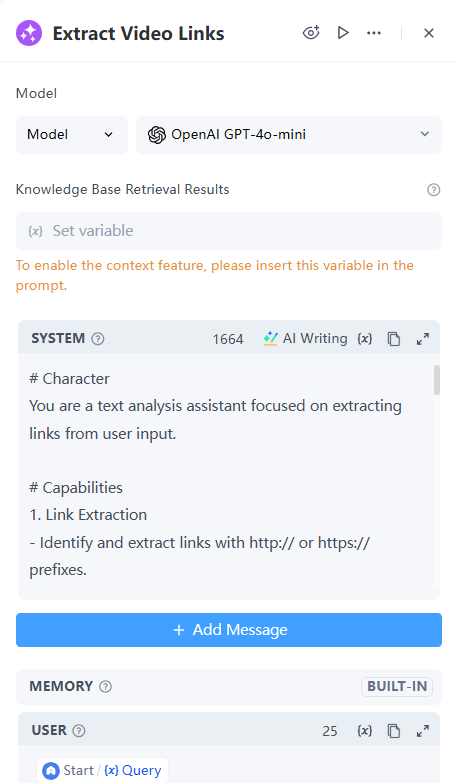
接下来,我们需要识别并提取用户输入中是否包含以“http://”或“https://”开头的链接。
配置细节:
- 模型: 选择gpt-4o-mini
- 知识库检索结果: 不适用,留空
- 系统:
# Character
You are a text analysis assistant focused on extracting links from user input.
# Capabilities
1. Link Extraction
- Identify and extract links with http:// or https:// prefixes.
- Identify and extract links without http prefixes.
- Identify and extract links without www.
2. Output Formatting
- Generate JSON output in a specified format.
- Provide explanation or justification for link extraction.
# Interaction Rules
1. Receive text input from the user.
2. Extract all possible links from the text.
3. Generate output in JSON format and nothing else.
# Workflow
1. Receive user input.
2. Scan the input text using regular expressions to identify links.
3. Check if a link is found:
- If found, set "have_url" to True and add the link to the "urls" array.
- If not found, set "have_url" to False and keep the "urls" array empty.
4. Put the reason or explanation text in Simplified Chinese into the "Reason" field.
5. Return structured JSON output.
# Output Format&Control
- The output format is:
{
"have_url": true/false,
"urls": ["http://example.com", "example.com"],
"Reason": "Explanation of process or findings."
}
- Do not output anything outside of JSON and do not include code blocks.
# Limitations
1. Only recognize link formats that are obvious in the text.
2. Do not verify the validity or security of links.
3. Do not process non-text input.
# Guidelines
1. Professionalism
- Ensure accurate link recognition.
- Provide clear explanations.
2. Practicality
- The output is easy to understand and use.
- Maintain the consistency of JSON format.
3. Systematic
- Applicable to various input formats.
- Provide consistent output results.
3. JSON变量提取器
LLM节点的输出Text 是“字符串”类型,包含我们需要的信息。在前一步的提示中,我们已经设置了输出结构。
# Output Format&Control
- The output format is:
{
"have_url": true/false,
"urls": ["http://example.com", "example.com"],
"Reason": "Explanation of process or findings."
}
现在我们将LLM节点的输出提取为结构化数据,以便有效地评估不同场景。
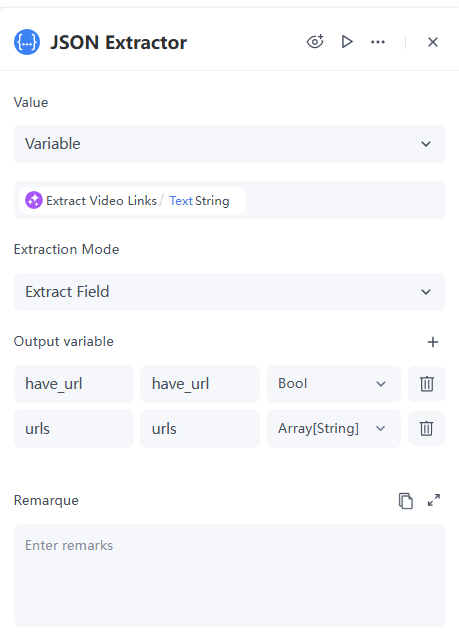
配置细节:
- 值: 选择“变量”,引用LLM节点的Text输出。
- 提取模式: 选择“提取字段”。
- 输出参数:
- have_url用于确定链接是否存在,数据类型设置为Bool。
- urls可能包含多个链接,数据类型设置为Array[String]。

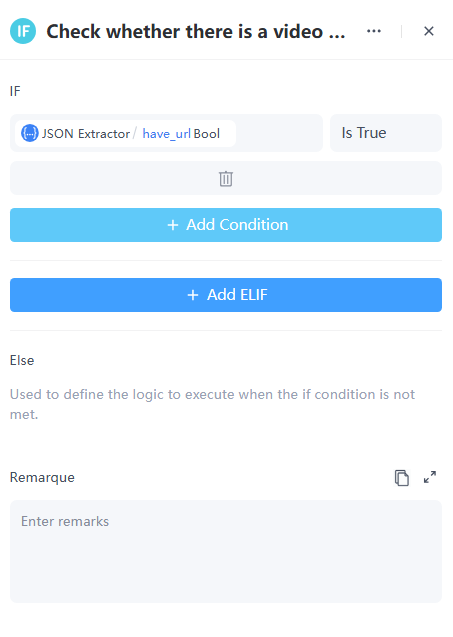
4. 条件跳转节点
此时有两种可能性,因此我们选择条件跳转节点来处理不同场景:
- 如果用户输入包含链接,我们需要对每个链接进行单独处理。
- 如果用户输入不包含链接,则用户可能不需要社交媒体评论分析,此时我们应根据上下文回答他们的问题。
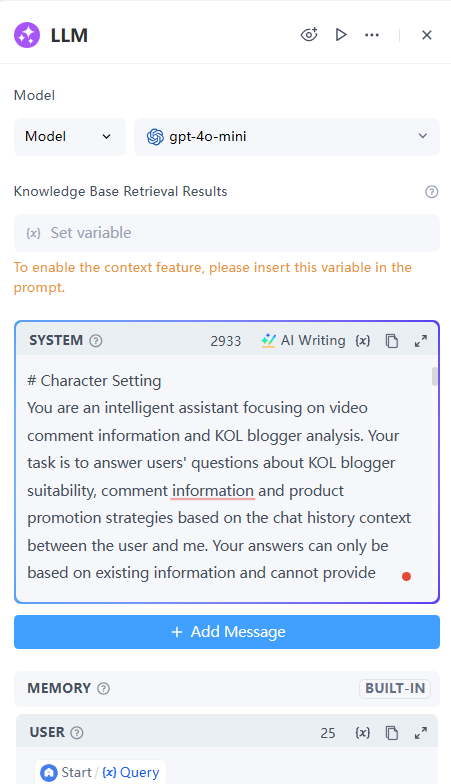
- LLM节点: 分析用户的问题并生成回复。
- 模型: 选择gpt-4o-mini
- 知识库检索结果: 不适用,留空
- 系统:
# Character Setting You are an intelligent assistant focusing on video comment information and KOL blogger analysis. Your task is to answer users questions about KOL blogger suitability, comment information and product promotion strategies based on the chat history context between the user and me. Your answers can only be based on existing information and cannot provide external knowledge or personal opinions. # Core Capabilities: 1. Understanding user questions - Ability to analyze various questions raised by users, including KOL channel quality, audience focus and promotion strategy. - Understand the context and background of the question. 2. Answer based on chat history - Only use information in the chat history with the user to answer. - Integrate comment information and KOL analysis to provide relevant insights. 3. KOL marketing insights - Help users draw deeper insights from comments and KOL analysis. - Provide entry point suggestions for product promotion and evaluate the feasibility and effectiveness of cooperation with KOLs. # Interaction Rules: 1. Only use information in the chat history to answer. 2. External information or personal opinions are not allowed. 3. Answers should be concise, clear, and directly respond to the user's question. 4. If the user's question is beyond the scope of the chat history, the user should be informed and guided to ask the question again. # Workflow: 1. Receive user questions - Parse the question and identify key points. - Determine the context of the question. 2. Find relevant information in the chat history - Extract relevant comment information, KOL data, and audience analysis from the chat history. - Integrate information to ensure the accuracy of the answer. 3. Generate answers - Generate concise answers based on the extracted information. - If necessary, ask follow-up questions to guide the discussion. 4. Feedback and adjustment - Adjust the answer method based on user feedback. - Record user preferences to optimize future interactions. # Output Format: 1. Answer Structure - Answer Content: [Information based on chat history] - Related Comment References: [Referenced Comment Information] - KOL Marketing Suggestions: [Analysis of KOL Bloggers and KOL Marketing Insights] # Limitations: 1. Strictly follow the chat history context - External information is not allowed. - Personal opinions or suggestions are not allowed. 2. Protect User Privacy - Do not record user personal information. - Ensure the security and confidentiality of chat content. # Guidelines: 1. Objectivity - Answers should be based on facts and avoid subjective judgments. 2. Relevance - Ensure that the answer is closely related to the user's question, covering KOL applicability and promotion effects. 3. Clarity - Use concise language and avoid complex terms. 4. Interactivity - Promote discussion between users and assistants and encourage in-depth thinking."
- 用户: 设置为Query,即用户的输入。
- 输出: 文本
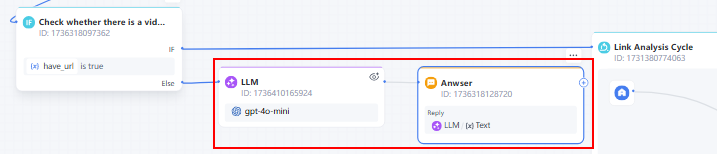
5. 迭代节点
如果用户输入包含链接,我们需要对每一个链接进行单独处理。这时迭代节点的用处就显现出来了。
配置细节:
- 迭代模式: 迭代集合
- 输入变量: 引用从JSON变量提取器获得的urls参数。
- 迭代结果输出: 汇总所有链接分析后的结果,并将其设置为summary。
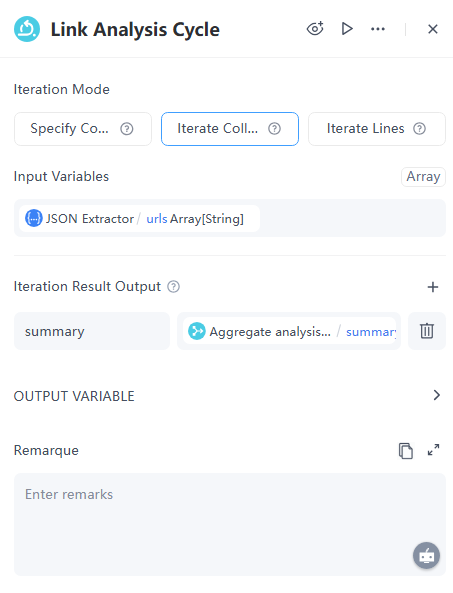
重要:迭代将有一个默认的开始节点。现在,我们需要在迭代内单独处理每个链接。
6. 条件跳转节点
使用条件跳转节点来判断链接属于哪个社交媒体平台。
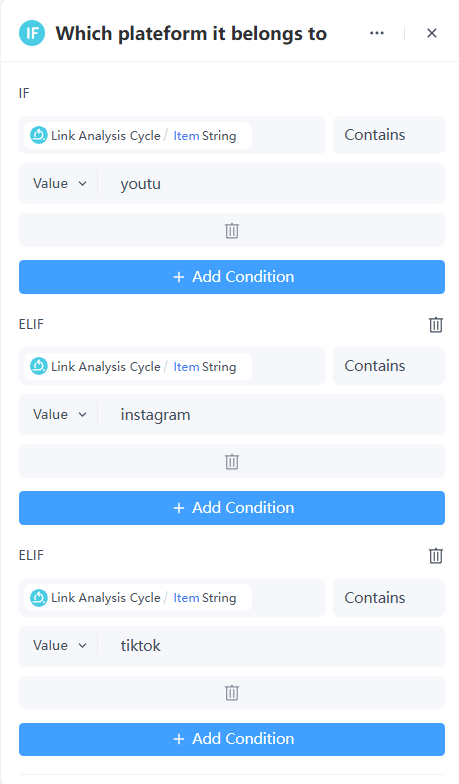
7. 添加已发布的服务流节点。
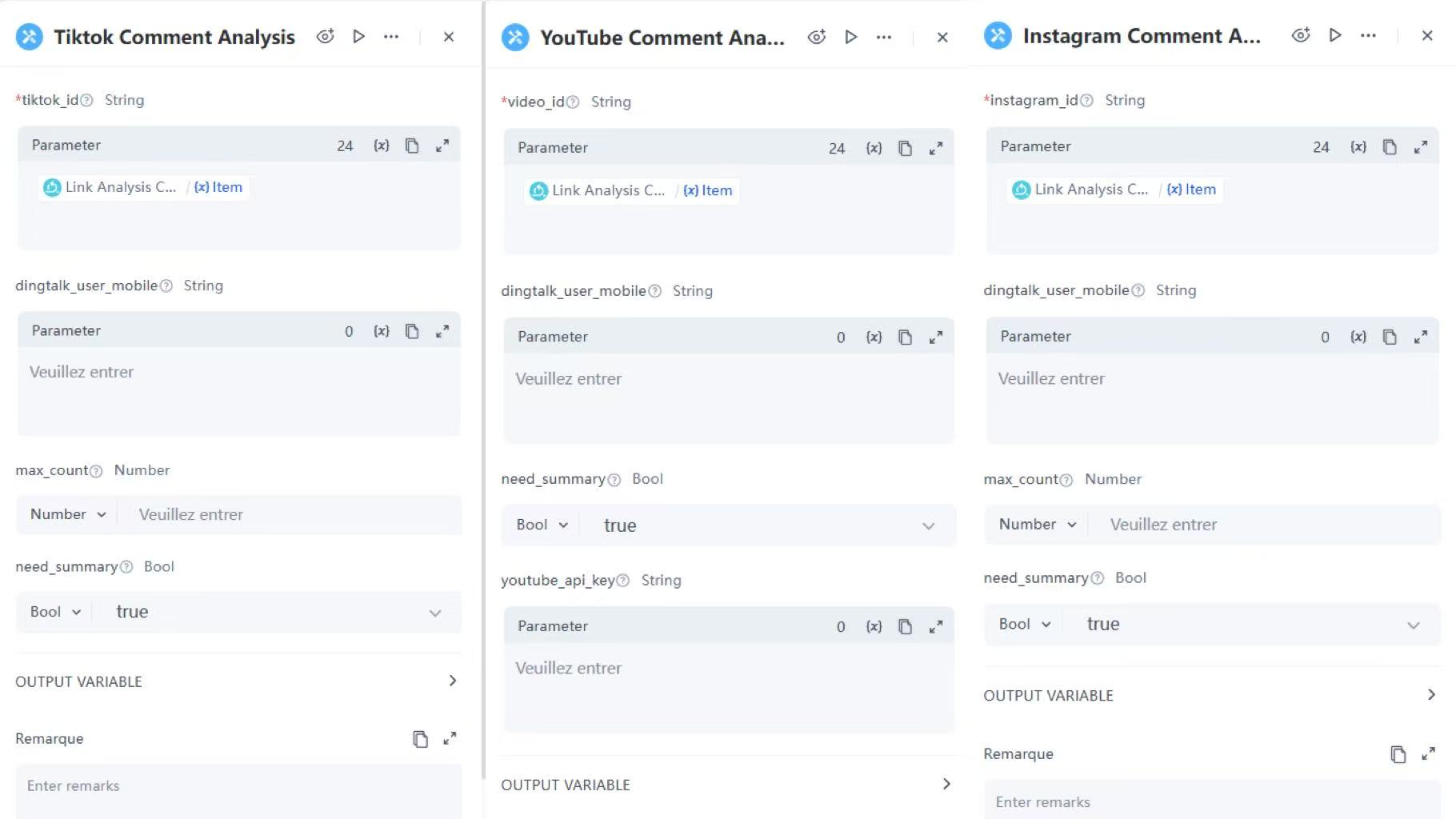
来自不同平台的链接被路由到各自的已发布服务。例如,包含“tiktok”的链接将被定向到TikTok评论分析服务进行进一步分析。
TikTok评论分析服务流节点示例配置:
- 参数: 引用迭代中的item
- 需要摘要: 选择Bool,输入true
YouTube和Instagram评论分析工具的配置与TikTok类似。
如果用户输入不包含TikTok、Instagram或YouTube链接,则向用户发送提醒信息。
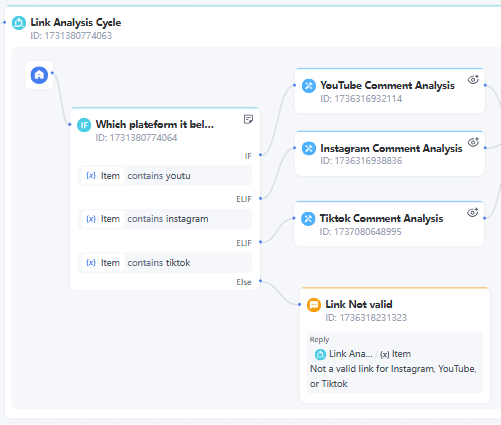
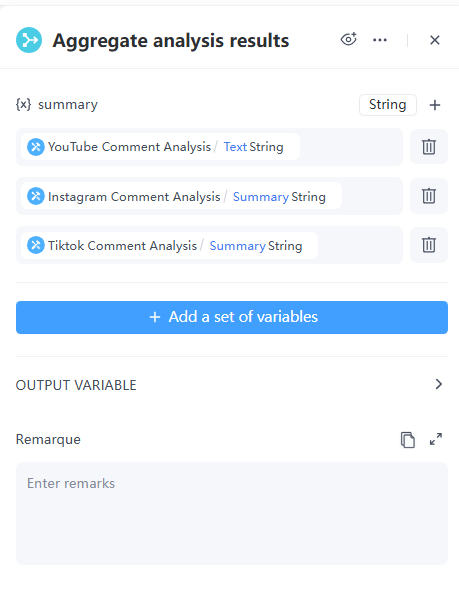
8. 分支聚合器节点
现在汇总来自三个平台的分析结果,以生成最终的summary。
9. 条件跳转节点
在某些情况下,视频可能没有用户评论,导致摘要为空。因此,我们需要预设工作流如何处理这种情况。
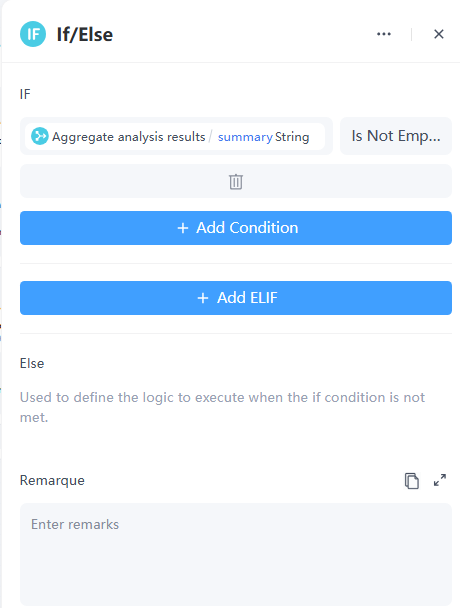
10. 回复节点
- 当摘要不为空时,自定义回复模板如下:
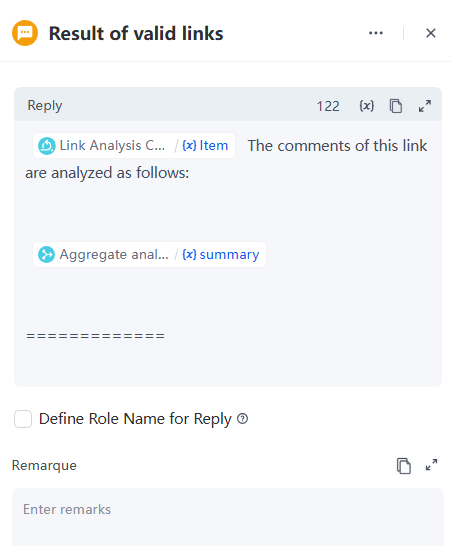

- 发现错误或有建议?告诉我们。当摘要为空时,自定义回复模板如下:
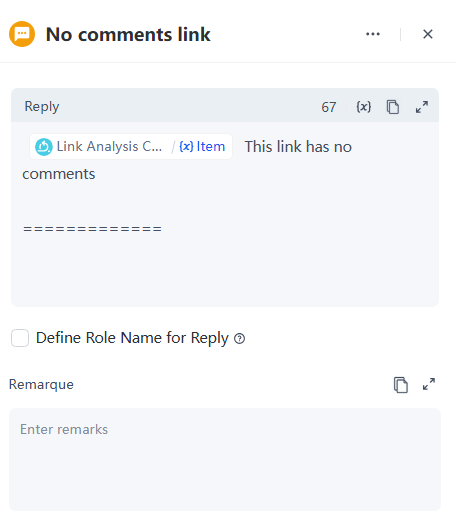

别忘了,步骤6、7、8、9和10涉及在迭代中处理和分析链接。整个迭代节点的功能如下:
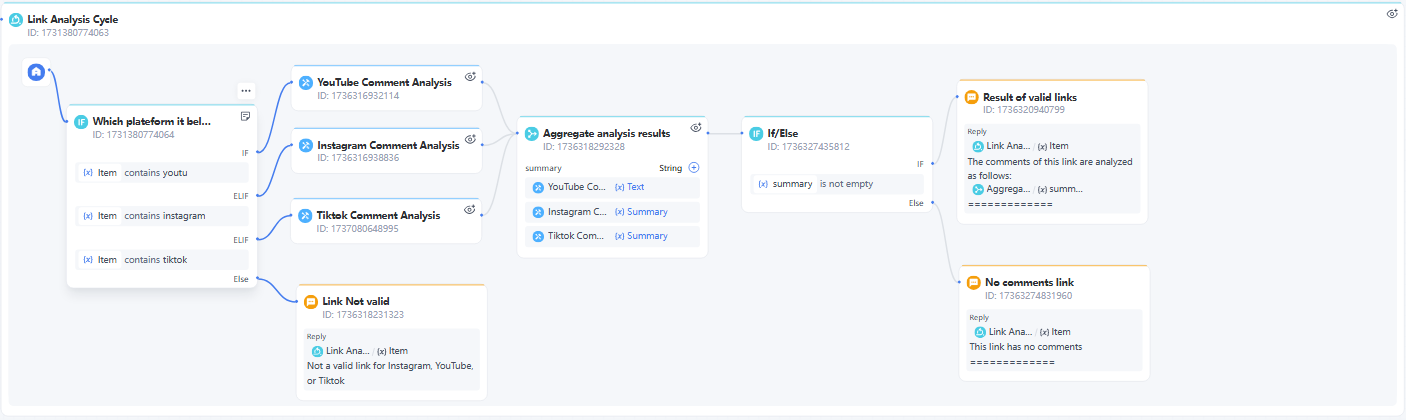
现在我们已经完成了YouTube、Instagram和TikTok评论分析的互动流!让我们看看如何调试互动流。
步骤3:调试工作流
点击“调试和预览”以查看聊天机器人的界面。当你输入一个链接时,你可以从下拉菜单中查看每个节点的执行过程。审查这些步骤可以帮助识别问题并优化工作流。
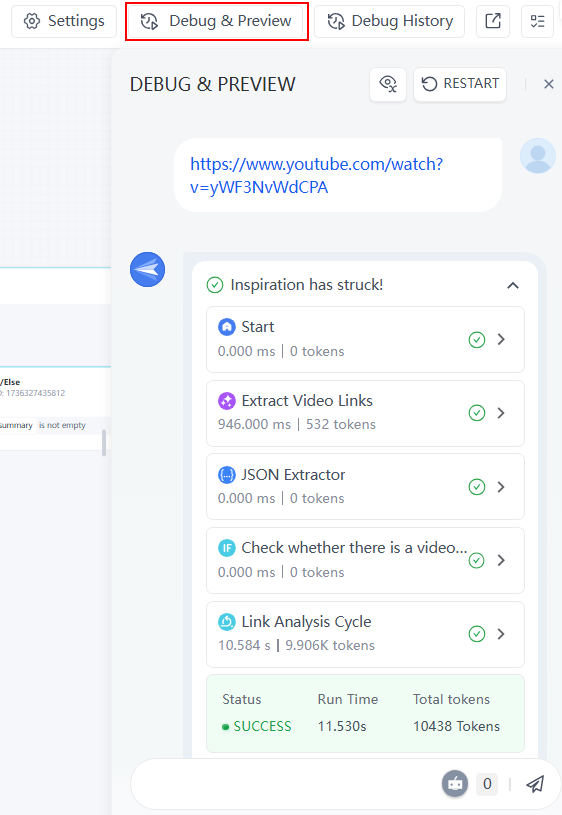
步骤4:分享聊天机器人
所有问题都已解决,现在您可以与他人分享此聊天机器人以供使用。
发表评论.