定义
LLM节点是GoInsight.AI工作流的核心组件,旨在处理复杂的文本和对话任务。它利用输入参数和提示词调用大语言模型(LLMs),执行内容生成、翻译、代码编写和基于知识的问答等任务。
在对话式工作流中,该节点支持会话记忆;在服务式工作流中,则提供灵活的调用模型,以满足各种业务需求的AI解决方案。通过选择合适的模型并优化提示词,您可以在对话模式和服务模式下构建可靠且高效的解决方案。
LLM节点参数:
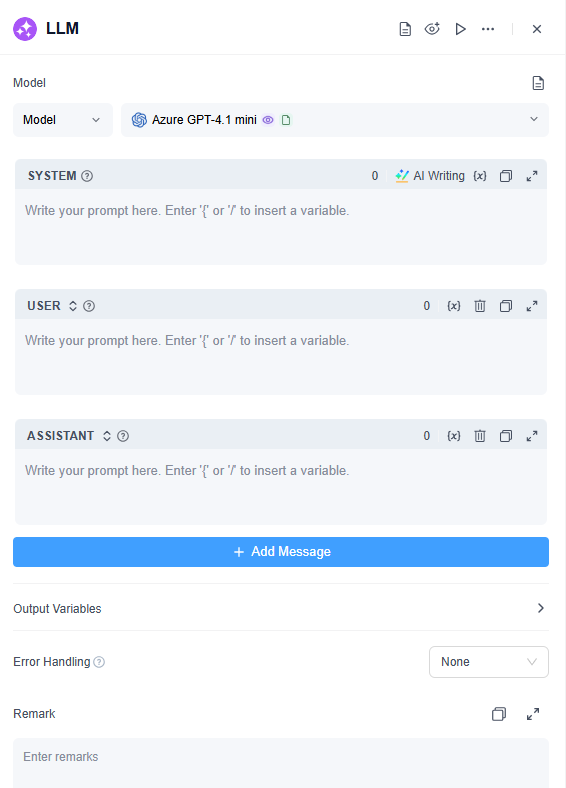
如何配置
1. 模型
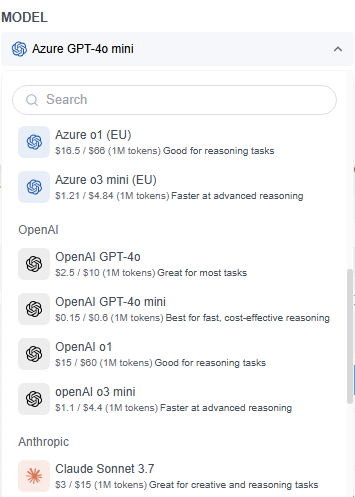
GoInsight.AI与多个领先的大模型集成,包括:
- Microsoft Azure GPT系列(GPT-4o, o1, o3 mini)
- OpenAI的GPT系列
- Claude Sonnet 3.7系列
- Gemini系列
- DeepSeek系列
选择模型时,请根据具体场景和任务类型,考虑安全性、推理能力、成本、响应速度和上下文窗口等关键因素。对于企业级解决方案,推荐使用Microsoft Azure GPT系列,因为它拥有强大的全球合规认证,可确保高标准的安全性和隐私性。
2. 模型温度
温度参数决定了生成文本的多样性。值越高,输出越具创意和多样性;值越低,则越可预测和逻辑。对于初学者,建议从默认的中等值开始。
| 配置选项 | 状态 | 描述 |
|---|---|---|
| 温度开关 | 关闭 | 模型的输出遵循固定的概率分布,结果更稳定和确定。这适用于需要高准确性和一致性的任务,例如参数提取和事实查询。 |
| 温度开关 | 开启 | 允许控制输出的多样性和随机性,因为模型的概率分布取决于所选温度值。 |
| 温度值 | 较高(接近1) | 生成更具多样性和创意的内容,但准确性和一致性可能降低。适合头脑风暴或开放性任务。 |
| 温度值 | 较低(接近0) | 模型输出分歧较少,生成更专注和可预测的结果,随机性有限。适用于需要精确和稳定输出的任务,例如数据提取。 |
4. 提示词编写器
LLM节点具有交互式的“提示词编排”部分,您可以在其中提供和编辑多段基于角色的指令。该部分包含多个组件,包括:
- 系统:定义模型的角色、风格和行为限制。例如,“你是一名法律顾问,请以简洁专业的语气回复。”(对于简单任务,所有提示词可直接写入系统框中。)
- 用户:代表用户的输入,例如对模型的提问或请求。
- 助理:在这里,您可以为模型提供答案示例,或存储您认为模型回答得很好的先前响应,以便在多轮对话中保持优质回答。
在提示词编辑器中:
- 使用 / 或 { 可快速调出变量插入菜单,您可以从上游节点或特殊变量块中选择变量。
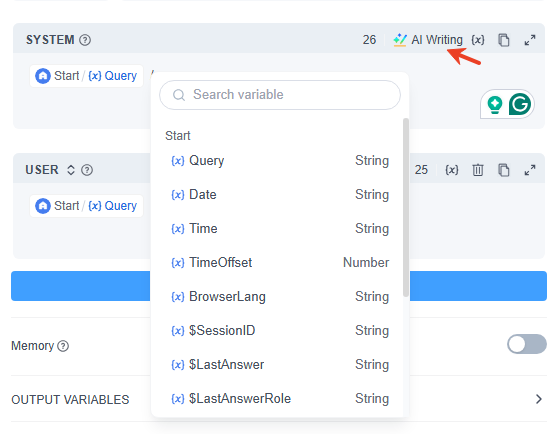

- 如果您缺乏灵感,也可以使用“AI写作”(AI辅助提示词编写)快速生成提示词,然后根据需要进行修改。
5. 记忆(在对话式工作流中启用)
当记忆功能启用时,与LLM模型的每次交互都包含会话历史。这使得模型能够更好地跟踪和理解用户意图及上下文,从而生成更自然、连贯的响应。
历史记录:模型在同一节点内最多可保留50条会话记录,该限制可根据需要从1调整到50。
记忆范围:进一步分为两种记忆类型:
- 会话记忆:记录每轮对话的完整输入/输出对。
- 节点记忆:保留当前LLM节点的输出,非常适合多智能体交互。
使用选项:用户可在“内置”和“变量”模式之间进行选择。
- 内置:系统会自动将最新的用户输入和相关上下文纳入提示词。
- 变量:您可以手动将过去的对话插入提示词中,因此适用于需要更精确控制的场景。
6. 输出变量
LLM节点的输出是其生成的文本内容。理论上,您还可以通过适当的提示词指示模型以不同格式生成输出,例如Markdown或JSON。
常见案例场景
LLM节点在对话模式和服务模式下均作为核心组件。它利用大语言模型的能力处理涉及对话、生成、分类和处理的任务。通过适当的提示词,它可以在工作流的不同阶段处理多种任务。
- 文本处理
- 它作为一个节点,根据给定主题和关键词创建文本内容(文章、摘要)。
- 内容分类
- 在邮件批处理过程中,它可自动将邮件分类为不同类型,例如询问、投诉或垃圾邮件。
- 意图识别
- 在客户服务对话中使用时,它能识别用户意图并将其路由到适当的下一个流程,确保速度和准确性。
- 代码生成
- 它展现出色的智能,能够根据用户需求生成特定的业务逻辑代码或测试用例。
- 情感分析
- 它可以分析角色扮演场景中的角色情感,并提出适合上下文的解决方案。
- RAG(检索增强生成)
- 在知识库问答场景中,它结合知识库数据与用户查询,提供精确且相关的答案。
简单案例:单节点调试
如果AI的响应不符合您的期望,请在单个LLM节点中多次使用“提示词编辑器”以微调其输出。请参考以下示例提示词获取实施指导:
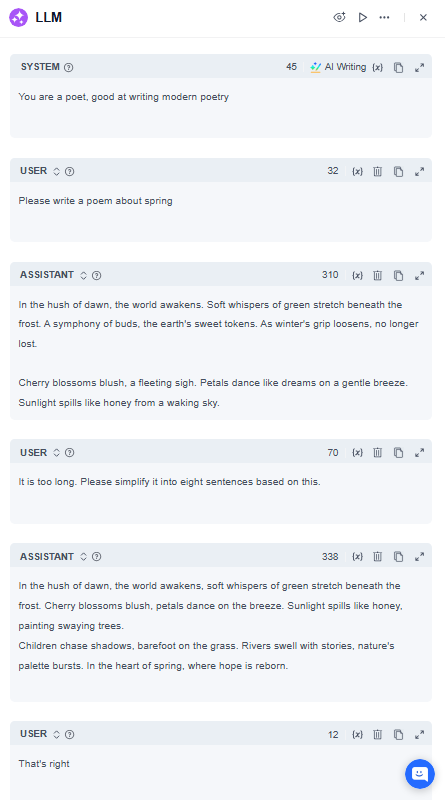
注意事项
- 避免在多个部分中插入相同的变量(例如,将变量A同时插入到系统和用户框中),因为这可能会导致模型混淆。
- 大语言模型有输入令牌的限制。建议避免一次性插入过多内容。对于较长的输入,可使用知识库功能有效管理大量信息。
- 对于具有复杂步骤的高复杂度任务,请避免使用单个大模型处理所有内容。相反,建议为每个步骤使用单独的LLM节点,以提高输出准确性并减少错误。
- 大模型有时会产生不一致的输出。如果结果不理想,进行多次迭代或优化提示词可能会带来更好的结果。
发表评论.