
- What is an LLM?
- How Do They Work?
- The Transformer Architecture
- Self-Attention Mechanism
- Prediction & Tokenization
- How LLMs Learn
- Pre-Training: Building the Foundation
- Instruction Tuning: Learning to Follow Directions
- Reinforcement Learning from Human Feedback (RLHF): Refining the Responses
- How We Interact with LLMs
- Prompt Engineering: Getting Better Results
- Hallucinations & RAG
- Pro Tip: A Smarter Way to Interact: GoInsight.AI's Insight Chat
- The Economy of LLMs
- LLMs' Challenges and The Future
You interact with AI every day—whether it's helping you write an email or plan a trip. Behind these seemingly magical abilities is a common engine: Large Language Models (LLMs).
So, what exactly are these LLMs? How do they learn, think, and even make mistakes? This article will break down LLMs, explaining in the most straightforward way how they work, how they learn, and what their future holds.
What is an LLM?
A Large Language Model (LLM) is a form of deep learning model designed to understand and generate human-like language. The "Large" in its name refers to two key characteristics that give it incredible power:
- Training Data: A massive amount of text from books, articles, websites, code, etc. This is the colossal body of information the model learns from.
- Parameter Scale: The billions of connections within the model's neural network act like intricate "knobs and dials." These parameters determine how the model processes information and learns patterns. Ultimately, the sheer number of these parameters allows the model to capture the nuances and complexities of language.
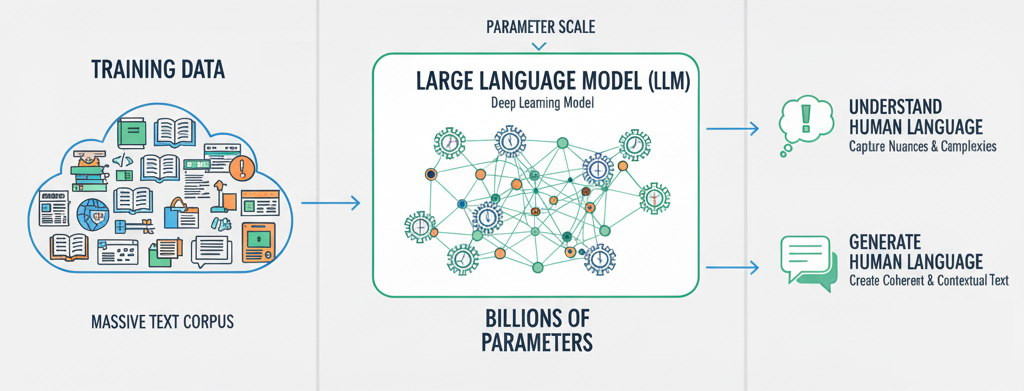
In short, the power of LLMs is a result of the synthesis of extensive training data and an immense number of parameters. Together, they enable the model to understand and generate language that can feel uncannily human.
How Do They Work?
The most simplified way to understand how LLMs work is that they're trying to predict what comes next.
They take a piece of text you provide and, based on the patterns they've learned from vast amounts of data, they predict the next most likely word. They then repeat this process, one word at a time, until they've generated a full response.
As an example, if you asked an LLM what comes next, after prompting "Once upon a…", the model knows that "time" is most likely the next word.
But to make this possible, LLMs rely on a powerful architecture, known as Transformer. This is the foundation of nearly all modern AI LLMs.
The Transformer Architecture
Transformer architecture is a neural network design introduced back in 2017.
It's the backbone of modern LLMs, and it revolutionized natural language processing with a "simple" trick; instead of processing words one by one, it processes the entire sentence and words simultaneously.
This parallel processing makes them faster and better at capturing long-range relationships by keeping track of connections between words, even if they're far apart.
But this is only effective because of the self-attention mechanism, the core of the Transformer architecture.
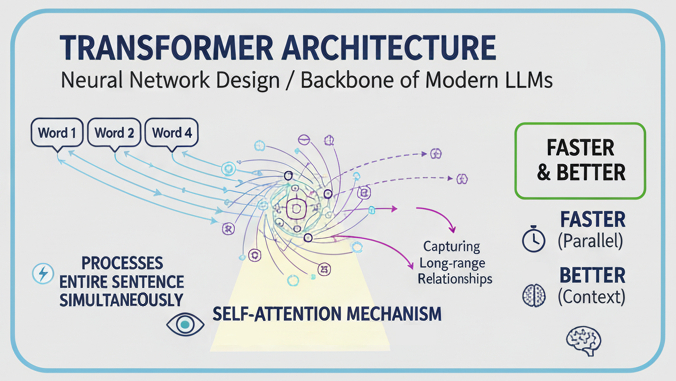
Self-Attention Mechanism
The most critical ability of the Transformer is the self-attention mechanism. The self-attention mechanism teaches the LLM to understand words and sentences, like a human does, by giving "attention" to words connected to other words.
We humans don't read sentences at each word in isolation; we understand how they connect to the other words in the sentence.
For example, in this sentence:
- "The dog chased the ball because it was fast."
In this example, the word "it" can mean the dog or the ball. To us, it's obvious, but to an LLM with no context, it can be confusing to know which it refers to.
But using the self-attention mechanism, an LLM assigns "weight" to the relationship between the words:
- Higher weight: "Ball" – "Fast"
- Lower weight: "Dog" – "Fast"
With these "weights", the model understands that the "it" refers to the ball.
Simply put, the self-attention mechanism helps the model figure out which word makes the most sense, based on context. It pays attention to all the words at once and decides which are the most important to "understand" the meaning of the sentence.
Prediction & Tokenization
At its core, LLMs are predictors or 'probability' machines. They use the words (tokens) you've provided, and predict:
- "What's the most likely next token?"
Then, they simply repeat this prediction to generate a full response.
This process is known as 'tokenization' and bridges the gap for the model to understand human language by converting it to machine-readable math.
Speaking of 'tokens', it's also important to understand what they are. LLMs don't actually process "words"; instead, they convert words and phrases into numerical codes, called "tokens".
For example: "I love pizza"
| Phrases | Tokens | Example IDs |
|---|---|---|
| "I love pizza" | ["I", "love", "pizza"] | [101, 546, 231] |
All in all, every task you give an LLM—from writing an essay to answering a question—is boiled down to predicting a sequence of these tokens.
How LLMs Learn
For the user, it's easy to simplify how LLMs work, thinking they "know" how to answer questions politely and follow instructions. But the reality is, it's not "innate" and a model has to go through rigorous post-training to tune its behavior.
But before that, there are multiple stages a foundational model has to go through to "evolve" into something useful:
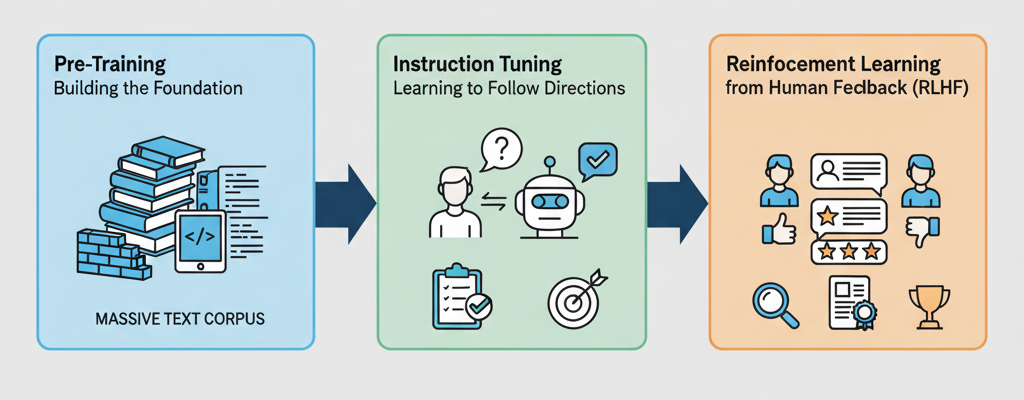
Pre-Training: Building the Foundation
In the pre-training stage, the model is trained on vast amounts of text from across the internet. The model is not provided with direct guidance; instead, it learns:
- Grammar & syntax.
- Facts & knowledge.
- Patterns in language.
At this stage, the model undergoes unsupervised learning and is left to its own devices to build up a general understanding of language.
Instruction Tuning: Learning to Follow Directions
With the knowledge it has gained in the pre-training stage, it is now 'smart', but not necessarily useful. At this stage, it might regurgitate information it learned, but often in nonsensical or irrelevant ways.
Here is where humans still play a significant role in AI, teaching the model to provide helpful and accurate answers with instruction tuning.
Developers will fine-tune the model with curated datasets, where each input (prompt) has a clear, correct output (response).
For example:
- Input: "Summarize this text in a single paragraph."
- Output: "This text discusses X, Y, and Z."
The goal here is to teach the model to behave in a way humans find helpful, while being accurate to the provided instructions.
Reinforcement Learning from Human Feedback (RLHF): Refining the Responses
The last stage is Reinforcement Learning from Human Feedback (RLHF). This is the final polish for the LLM to feel "aligned" with human expectations. The process happens in three main steps:
| Step | What Happens |
|---|---|
| 1. Data Collection | Humans rank different model responses to the same question to collect data on the humans' preferences for answers. |
| 2. Reward Model | Trains a smaller model based on the rankings to predict the kind of answer humans rate higher. |
| 3. Optimization | The model is adjusted to maximise its tendency to produce higher-scoring responses, reinforcing higher-scoring answers more often. This improves the model's helpfulness, accuracy, and safety. |
Let's break it down into something relatable. LLMs "learn" the same way you train a dog.
- Pre-training is like the basic instincts of a dog (barking, running, sniffing).
- Instruction tuning is like giving it commands to learn certain things, like sitting, fetching, or spinning.
- RLHF is like the treats or praise you provide to reinforce good behavior.
How We Interact with LLMs
LLMs are already heavily ingrained into our daily lives, with many utilizing their power to do a variety of tasks:
- Content Creation: Writing blogs, marketing copy, social media posts, etc.
- Information Summaries: Summarizing and condensing long reports/transcripts into key points with actionable insights.
- Question & Answering: Virtual assistants answering factual queries.
- Customer Support: Chatbots to handle common issues before escalating to a human agent.
- Code Assistance: Writing, debugging, and assisting with coding.
LLMs have plenty of use cases, but the reality is that, depending on the information provided/prompted, the results may vary. The way you phrase your request (prompt) can have a huge effect on the output, which is where "prompt engineering" comes into play.
Prompt Engineering
The idea behind prompt engineering is simple; providing as much direct, relevant information to get a better output (response). For example:
| Example Prompt | Output Quality |
|---|---|
| Write about cats | Too broad, vague/irrelevant response |
Write a 3-4 paragraph blog post of around 500 words about why cats are great pets for families. Include specific breeds of cats and factors like loyalty, playfulness, and colors. Add a section about costs associated with owning a cat to end the post. | Focused, structured, highly-specific, useful response tailored to your needs. |
In short, the more information you provide, the better the response will be.
There are also other 'techniques' you can utilize for better prompting & responses:
- Role Prompting: Assign the model an identity for it to frame its response.
- E.g., You are an expert historian…
- Few-Shot Prompting: Provide multiple examples for the model to base its response on your example.
- Summarize the following paragraph in one short sentence.
- Text/Summary Example 1…
- Text/Summary Example 2…
- Text/Summary Example 3…
- Now summarize this paragraph following the same structure.
- Provided Text… Summary:
- Scenario Prompting: Provide a specific scenario/situation for the model to respond within that context.
- Imagine you're explaining phishing attacks to a group of 10th graders at a school assembly. What would you say?
There are plenty of other prompting techniques, like Chain-of-Thought prompting, which can be especially useful to solve complex problems. With this method, you guide the LLM to perform multi-step reasoning by adding specific instructions like "Think this through step-by-step".
Hallucinations & RAG
However, there are also instances where LLMs can get things wrong. These are called "hallucinations", where the model confidently provides objectively false answers. They don't know they're wrong, and if you don't verify their response, you won't know they're wrong either.
To counteract this, many modern models use Retrieval-Augmented Generation (RAG). Simply put, RAG verifies the validity and accuracy of the model's response by:
- Searching through trusted external databases and documents.
- Reviewing real, up-to-date information online.
This doesn't completely remove hallucination out of the equation, but it does provide models a way to balance creativity with factual reliability.
A Smarter Way to Interact: GoInsight.AI's GoInsight Workspace
For most companies, the real challenge isn’t just understanding advanced AI techniques like RAG—it's making these powerful methods accessible to every employee. This is where GoInsight.AI's GoInsight Workspace comes in. It's more than just a chatbot; it's an all-in-one platform that makes advanced AI simple to use for everyone.
GoInsight.AI's GoInsight Workspace brings AI from a few experts to your entire company, turning knowledge into action. Here's what makes GoInsight Workspace a powerful tool for your entire company:
- One-Click Deployment: Builders can turn complex AI workflows into simple commands or cards, making them instantly available to all team members.
- Built-in Safety: The platform ensures that only approved and compliant workflows are accessible in the chat, keeping every action secure and auditable.
- Flexible Models: It integrates top-tier LLMs, like ChatGPT and Gemini, allowing you to easily switch between different AI engines to find the best fit for any task.
The Economy of LLMs
The LLM ecosystem is divided into two main approaches. Depending on your needs, the model of your choosing may differ:
| Approach | Examples | Pros | Cons |
|---|---|---|---|
| Closed-Source (Proprietary) | ChatGPT (Open AI), Gemini (Google) | High-performance, user-friendly, strong support, latest innovations/tools. | Expensive, less transparent, limited customization. |
| Open-Source | LLaMa (Meta), Mistral | Free or cheaper than closed-source models, highly customizable, active community support. | Often requires technical expertise, can be less polished. |
The Costs of LLMs
That said, regardless of the type of LLM, running one is expensive, with two main categories of costs to consider:
- Training Cost: The initial investment into data, computing power, and engineering, which can cost millions of dollars.
- Inference Cost: The ongoing cost of generating outputs for users. Every prompt you send requires GPU time, electricity, and infrastructure.
This is the reason why certain models limit free usage or require subscriptions to access.
LLMs' Challenges and The Future
The Challenges Now
That said, the reality is that LLMs currently have multiple challenges they've yet to overcome. Some of these include:
- Bias: If training data contains bias, the model may reproduce or amplify it.
- Privacy & Security: Possibility of sensitive data being leaked or misused for harmful purposes.
- Hallucinations: Confidently giving wrong answers, leading to misinformation and distrust.
- Context Window Limit: Models can currently only "remember" a limited amount.
- Energy & Cost: Training and running LLMs is expensive & resource-intensive.
The Future of LLMs
Despite these challenges, there is steady progress in LLM development that hint at possible futures of AI models:
- Multimodal Models: Systems that can process not only text, but also images, audio, and video. This makes much more complex queries and responses possible.
- LLM Agents: Fully-fledged, dynamic agents that can plan, take action, and perform complex tasks autonomously. Like a real, human coworker rather than an assistant bound by limitations like training data & instructions.
Conclusion
Large Language Models have quickly become the most transformative technology in the 21st century. While the way they work is enigmatic to the everyday user, hopefully, our guide has dispelled the mystery of how LLMs actually work.
Yes, LLMs still have limits, but every new generation pushes the boundaries of what's possible. The future isn't about humans versus AI; it's about how the two can work together to solve problems, unlock creativity, and redefine what's possible in everyday life.





Leave a Reply.