
- Why Train an LLM (Large Language Model)?
- How to Train an LLM: The Complete Process
- 1. Collecting and Cleaning Data
- 2. Choosing a Model Architecture
- 3. Understanding Compute Requirements
- 4. Training the Model
- 5. Evaluation and Testing
- 6. Deployment and Optimization
- The Challenges and Costs of LLM Training
- Enterprise-Ready AI for Secure LLM Integration: GoInsight.AI
- Final Words
- FAQs
Training AI LLM (Large Language Model) might sound like something only tech giants with endless GPUs can do. But if you've ever wondered what actually goes into creating one of these powerful AI models, you're not alone.
In this article, we'll walk through the basics of how LLMs are trained, what challenges you might face, and what practical options exist if you're curious about building something of your own without needing a supercomputer.
Key Takeaways:
💡 Strategic use beats raw power: You don't need to train a massive model to gain value. Thoughtful fine-tuning, contextual integration, and workflow design often deliver bigger impact than sheer scale.
💡 Data is your compass: Your AI is only as smart as the context you give it. Connecting the right knowledge sources transforms a generic model into a practical, reliable assistant.
💡 Focus on solutions, not obstacles: Complexity and cost are real, but they shouldn't stop you from exploring AI. Tools like GoInsight.AI let you experiment and innovate without getting lost in infrastructure.
Why Train an LLM (Large Language Model)?
You might be wondering, why go through the effort of training a large language model at all? The answer comes down to control, customization, and impact. Off-the-shelf models are powerful, but they're designed for general purposes. Training lets you adapt a model to your specific needs, whether that's understanding industry jargon, answering customer questions accurately, or generating content in a unique style.
There are several reasons organizations and individuals pursue LLM training:
- Domain Expertise – A general model might not understand your company's niche or specialized language. Fine-tuning lets the AI learn the context that matters most to your field.
- Better Accuracy and Relevance – By exposing the model to high-quality, relevant data, you increase the chances that its outputs are useful and precise for your tasks.
- Brand Voice and Style – Training allows the AI to reflect your preferred tone, terminology, and communication style, which is important for marketing, customer support, or internal tools.
- Experimentation and Innovation – Even small experiments with fine-tuning can reveal surprising insights, new automation opportunities, and ways to enhance workflows that off-the-shelf models can't provide.
Ultimately, training an LLM is about turning a generic AI into a tool that works exactly the way you need it to.
How to Train an LLM: The Complete Process
So, how does training an LLM actually work? Let's break it down step by step. Don't worry, we'll keep it high-level so you get the big picture without needing a PhD in machine learning.
1. Collecting and Cleaning Data
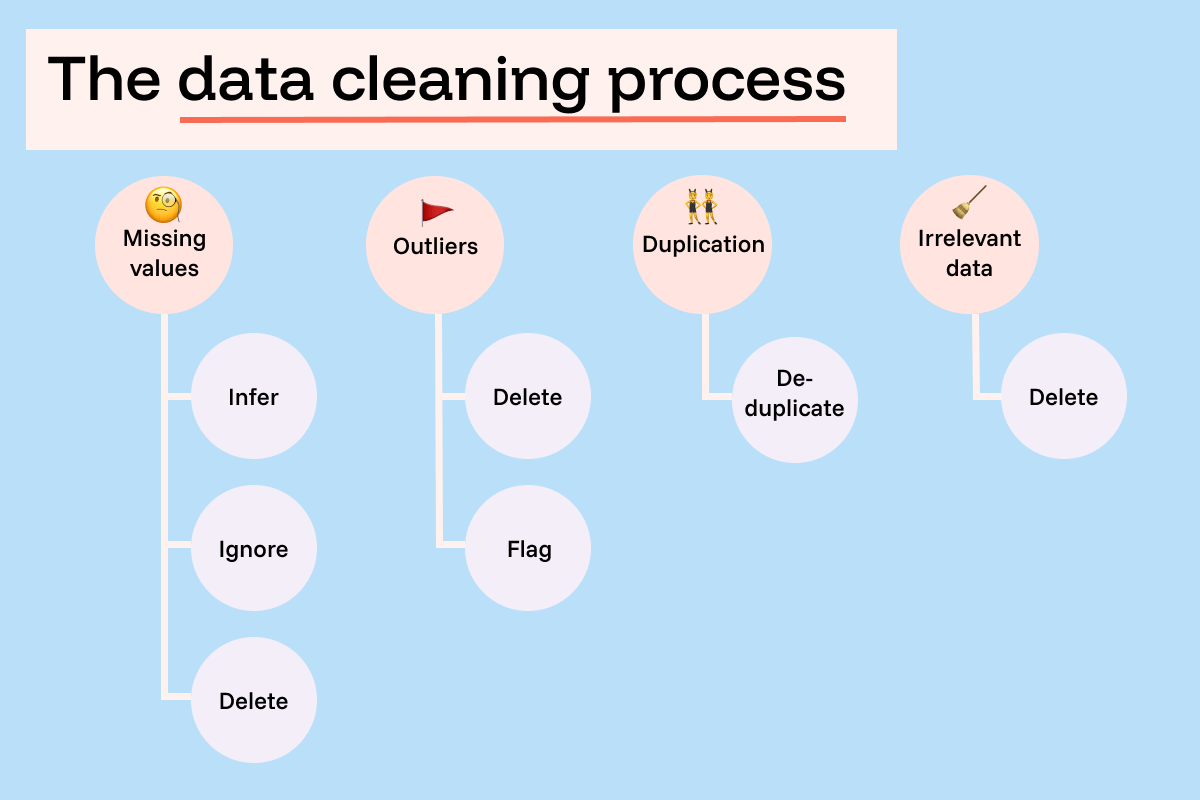
Every LLM is only as smart as the data it's trained on. The first step is gathering huge amounts of texts, such as book articles, conversations, even code. But here's the catch: more data doesn't always mean better results. Quality matters just as much as quantity. Duplicated, irrelevant, or biased text can lead to a model that gives poor or even harmful answers. That's why cleaning and filtering the dataset is so important. Think of it as teaching: you want your "student" to read the best material, not a pile of messy notes.
2. Choosing a Model Architecture
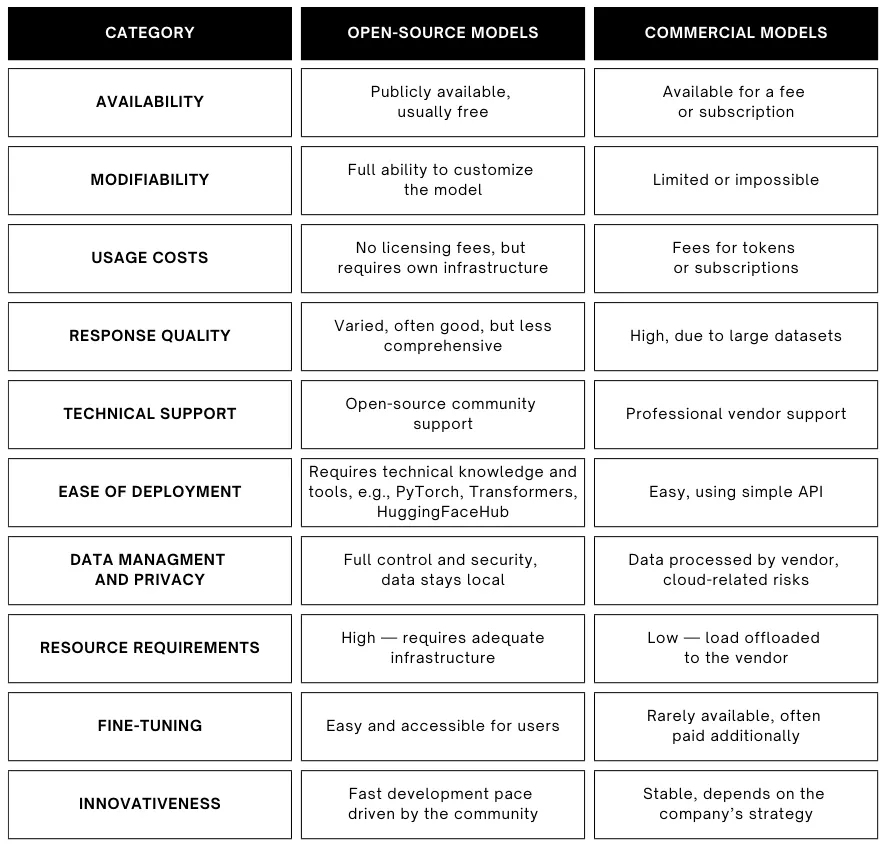
Most modern LLMs are based on a design called the Transformer. It's the secret sauce behind GPT, LLaMA, and almost every cutting-edge model today. You don't always need to reinvent the wheel here. Most organizations today don't train from scratch. Instead, they choose an open or commercial base model, and customize it to fit their needs.
- Open-source models (like LLaMA, Falcon, or Mistral) are available for anyone to use and modify. They're a great way to experiment if you have some technical skills and want more control.
- Commercial models (like those from OpenAI or Anthropic) are accessed through APIs. You don't need to worry about infrastructure, but you're tied to their pricing and terms of use.
3. Understanding Compute Requirements
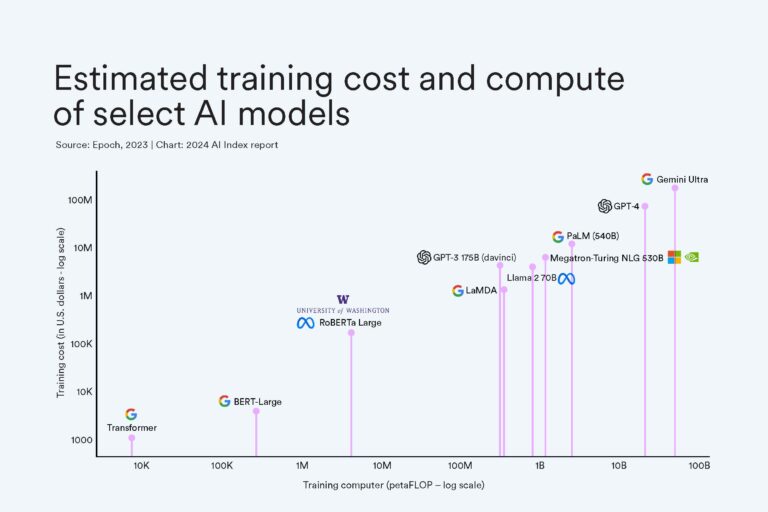
Here's where things get serious. Training a large model isn't something you can do on your laptop (unless you're very patient and the model is tiny). Big LLMs need massive computing power, with hundreds of GPUs or specialized TPUs running in parallel for weeks or months. That's why full-scale pre-training is typically done by tech giants or well-funded labs. For smaller teams, fine-tuning an existing model is a much more realistic path, since it requires far fewer resources.
4. Training the Model
When it comes to actually "training" an LLM, there are two main approaches: pre-training and fine-tuning.
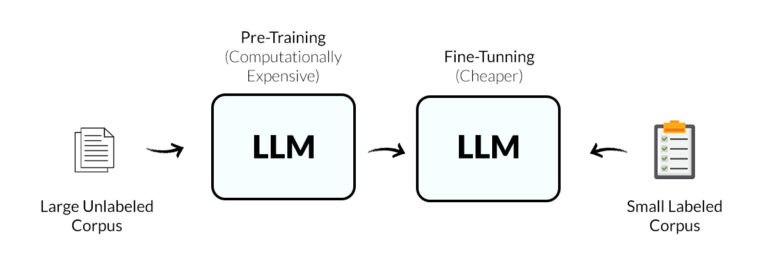
- Pre-training means starting from scratch, feeding the model massive amounts of text so it can learn grammar, facts, and reasoning patterns. This approach is extremely resource-intensive, requiring clusters of GPUs running for months, and is usually only attempted by large AI labs.
- Fine-tuning is far more practical for most individuals and organizations. You start with an existing base model and adapt it to a specific domain, task, or style. For example, a company might fine-tune a model to understand internal documents, industry-specific terminology, or customer support dialogues. Fine-tuning usually involves a smaller dataset, fewer computing resources, and a shorter training cycle, making it a realistic way to create a custom LLM without starting from zero.
- Enterprise Security: Data privacy is built-in. Role-based access, audit trails, and on-prem deployment keep your data secure.
- Knowledge Base + RAG: Connect your own data to make AI responses context-aware. Integrates knowledge bases and RAG seamlessly.
- Multiple Model Options: Work with leading LLMs and switch anytime to fit your use case or budget. Flexibility ensures you're never locked into one vendor.
- Visual Workflow Builder: Skip code and complex infrastructure. Drag-and-drop interface lets you design AI workflows in minutes.
In short, while pre-training builds a model from the ground up, fine-tuning lets you leverage existing models efficiently, tailoring them to your unique needs with manageable costs and effort.
5. Evaluation and Testing
Once trained, the model needs to be tested. Researchers use benchmarks like MMLU or SuperGLUE to measure reasoning and comprehension, but practical testing matters too. If you're building a support chatbot, does it actually answer customer questions correctly? If you're building a medical assistant, does it avoid giving risky or misleading advice? Testing ensures the model isn't just smart on paper, but useful in the real world.
6. Deployment and Optimization
Finally, the model has to be deployed so people can actually use it. This involves making it fast enough to respond in real time, scaling it to handle lots of users, and controlling costs. Techniques like quantization, distillation, and caching help models run efficiently without losing too much quality. For many teams, deploying a smaller, optimized model that runs cheaply is far better than chasing the biggest model possible.
The Challenges and Costs of LLM Training
By now, the process might sound exciting. But the truth is training a large language model is one of the most resource-hungry projects in AI. Let's break down the biggest challenges:
Expensive Compute Power
Training a modern LLM from scratch requires massive GPU clusters that can easily cost millions of dollars in compute. Even a scaled-down experiment can burn through your budget quickly if you're not careful.
Massive Amounts of Data
We're not talking about a few gigabytes of text. A serious LLM often needs hundreds of gigabytes to terabytes of clean, diverse, and domain-relevant data. Collecting, cleaning, and storing that much data is a huge project in itself.
Security and compliance matter
If your data contains sensitive information, such as customer conversations, internal documents, or financial records, you need to be absolutely sure the process is secure and compliant with regulations. That's often more than a weekend project.
High Team Expertise
Building an LLM isn't a one-person task. You need a team with strong skills in machine learning, data engineering, and distributed systems. Without this, even setting up the training pipeline can feel overwhelming.
Long Training Cycles
Finally, time. Training and fine-tuning runs can take weeks or even months, depending on the model size and resources. And if you make a mistake with hyperparameters? You might have to start all over again.
Enterprise-Ready AI for Secure LLM Integration: GoInsight.AI
Training your own LLM might sound powerful, but for most enterprises, it brings more risk than reward. Data exposure, compliance challenges make it impractical. What businesses truly need is a secure, enterprise-ready way to apply LLM intelligence to their own data, and that's exactly what GoInsight.AI delivers.
Goinsight.Al connects enterprises to trusted, compliant LLMs such as those from Microsoft Azure OpenAI service, ensuring no model training, zero data retention and ensure data residency. Goinsicht.AI also enables organizations to build AI systems that understand their unique content and workflows by connecting Internal Knowledgebase and RAG, it ensures your data remains protected and fully under your control.
So, what makes GoInsight.AI different?
With GoInsight.AI, enterprises can harness the intelligence of LLMs safely and effectively, turning their own knowledge into action without the risks of model training.
Final Words
Training AI LLM might seem daunting, but the bigger lesson is about understanding how AI learns and how you can harness it effectively. With the right approach and tools, you can start small, iterate fast, and gradually unlock powerful capabilities. So don't just read about LLMs—try building your own workflows, test ideas, and see how AI can work for you today.
FAQs





Leave a Reply.