LLM Comparison: A Guide to Evaluation & Selection
Before we begin
GoInsight.ai lets you build and customize your own AI-powered workflows. With multiple integrated LLM models to choose from, you can tailor the perfect solution for your business.

Before we begin
Manual thank-you email personalization is often inefficient.
GoInsight.ai builds workflows to instantly send personalized thank-you emails, boosting connections.
Selecting an LLM isn't about picking the one with the highest benchmark score. It's about finding the model that delivers on your unique requirements.
We've created this in-depth guide to give you a powerful, proven framework for LLM comparison.
You'll learn exactly how to evaluate models based on four key pillars and conduct real-world tests to ensure you make the best decision for your project.
The 4 Pillars of LLM Evaluation
To simplify the process, we're using 4 main "pillars" you can use to evaluate any model:
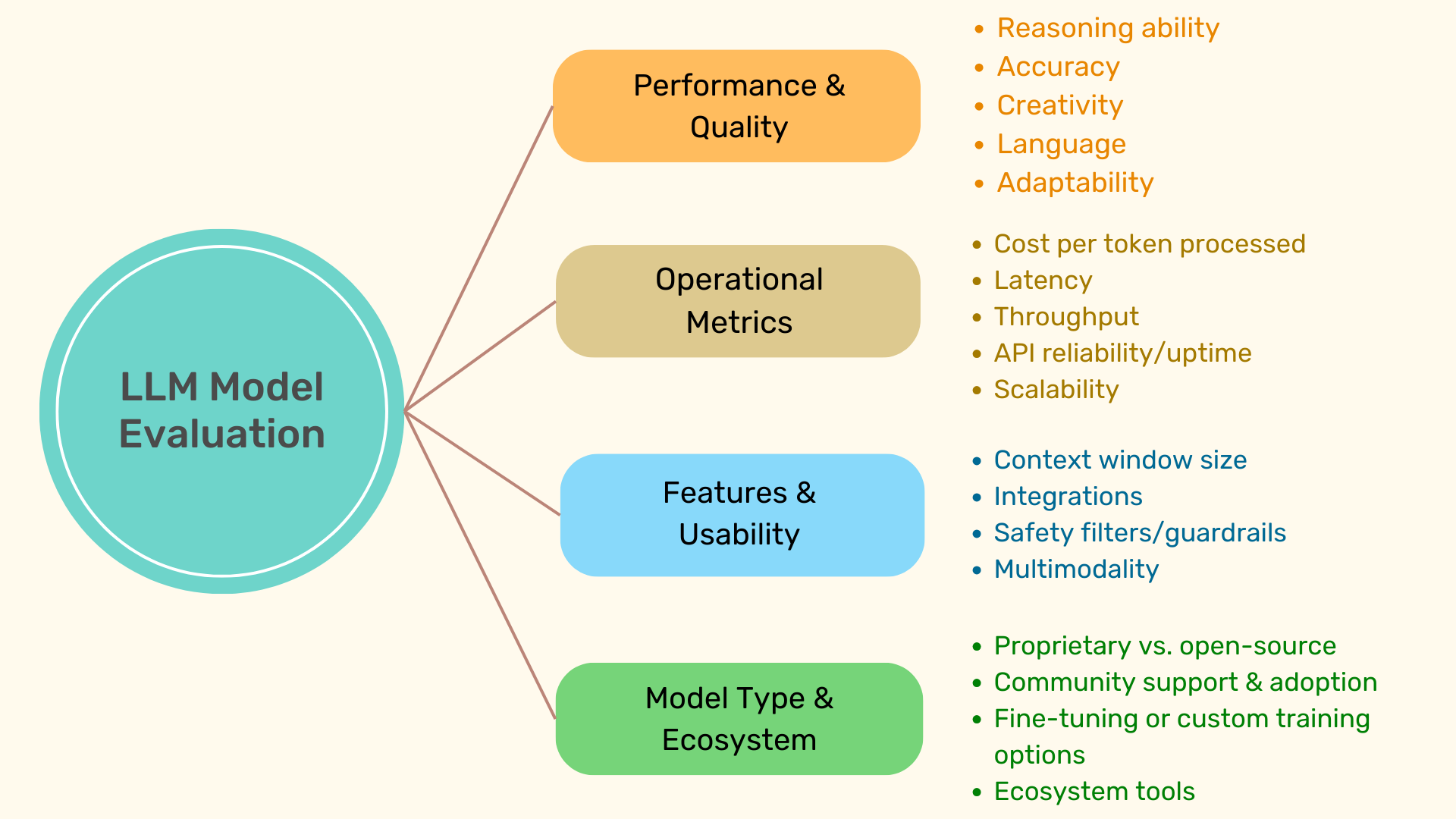
1. Performance & Quality – The Model's IQ & EQ
This pillar measures how 'smart' and 'socially intelligent' a model is.
'Performance' typically includes factual accuracy, reasoning, and depth of knowledge. 'Quality' is determined by the model's creativity, fluency, and whether it provides natural-sounding responses.
Evaluation Points:
- Reasoning ability (solving math or logic problems)
- Accuracy (how often it 'hallucinates' or makes up facts)
- Creativity (how creative its responses are)
- Language (grammatical correctness, clarity, flow, and fluency)
- Adaptability (e.g., how effective it is at switching between casual/professional tones)
For example, ChatGPT 4o is well regarded for its reasoning capability, while Claude 3.5 Sonnet's writing feels and reads more emotionally nuanced and human-like.
2. Operational Metrics – The Model's Efficiency & Cost
This pillar is straightforward and is an important consideration for businesses. This includes the cost to run the model, how fast it delivers results, and whether it can scale for large volume requests.
Evaluation Points:
- Cost per tokens processed (usually measured in 1,000 or 1 million tokens)
- 1 token typically ranges between 3-4 characters.
- Latency (how fast/slow the model responds)
- Throughput (rate of generated tokens per second)
- API reliability/uptime (consistency of performance)
- Scalability (if it can handle thousands of requests and grow with your needs)
For example, for low-cost, high-volume workflows, Mistral Medium 3 is well known for its value and dramatically lower token charges. Whereas for premium performance at scale, GPT-4.5 has significantly higher costs but is designed for top-end performance.
3. Features & Usability – The Model's Toolkit & User-Friendliness
This pillar considers the model's usability in real-world applications. Even a smart model can fall short if it doesn't fit your workflow.
Here are a few evaluation points to consider:
- Context window size (relates to how much text it can process at once)
- Integrations (how well it integrates with existing systems, e.g. APIs, plugins, ecosystem support)
- Safety filters/guardrails
- Multimodality (how flexible is the model? Can it process/generate text, images, code, etc.?)
For example, Claude Sonnet 4 has a large 200K token context window, allowing for analyzing large volumes of text (books, legal documents, long-form reports, etc.).
4. Model Type & Ecosystem – The Model's Origin & Community
The last pillar focuses on the model's origin and surrounding ecosystem. Proprietary models are polished but closed; open-source offers flexibility with higher setup effort.
Consider these evaluation points for your use case:
- Proprietary vs. open-source
- Community support & adoption
- Fine-tuning or custom training options
- Ecosystem tools
For example, Llama 3 is a popular, widely adopted open-source model with an active developer community. This makes it a flexible choice if you require fine-tuned control.
The LLM Comparison Toolkit
To make your LLM comparison data-driven, use these three essential tools:
| Tool | Purpose | Focus |
|---|---|---|
| Hugging Face Leaderboard | Measure raw performance | Academic benchmarks: Math, Reasoning, General Knowledge |
| LM Arena | Evaluate real-world usability | A/B testing, Crowdsourced votes, User preferences |
| Artificial Analysis | Get business-centric metrics | Cost, Speed, Token efficiency, Business viability |
1. For Book Smarts: Hugging Face Open LLM Leaderboard
Purpose: Measuring raw performance ("IQ") with academic style benchmarks.
Why it's helpful:
- Scores models on math, reasoning, programming, science, and general knowledge tasks
- Useful for comparing models' intelligence based on standardized tasks
- Wide variety of task types for easy comparison of 'knowledge' capability
- Highlights models with strong reasoning
2. For Street Smarts: LM Arena
Purpose: Evaluates a model's "EQ" and real-world usability using A/B testing.
Why it's helpful:
- Measures real-world usability by 'crowd-sourcing' votes in head-to-head comparisons of AI model outputs
- Showcases models that are adept at communicating, persuading, or entertaining
- Clearly segments tasks by categories (text, WebDev, vision, text-to-image, search, etc.)
- Provides a clear benchmark of users' preferences for different models' outputs
3. For Business Metrics: Artificial Analysis
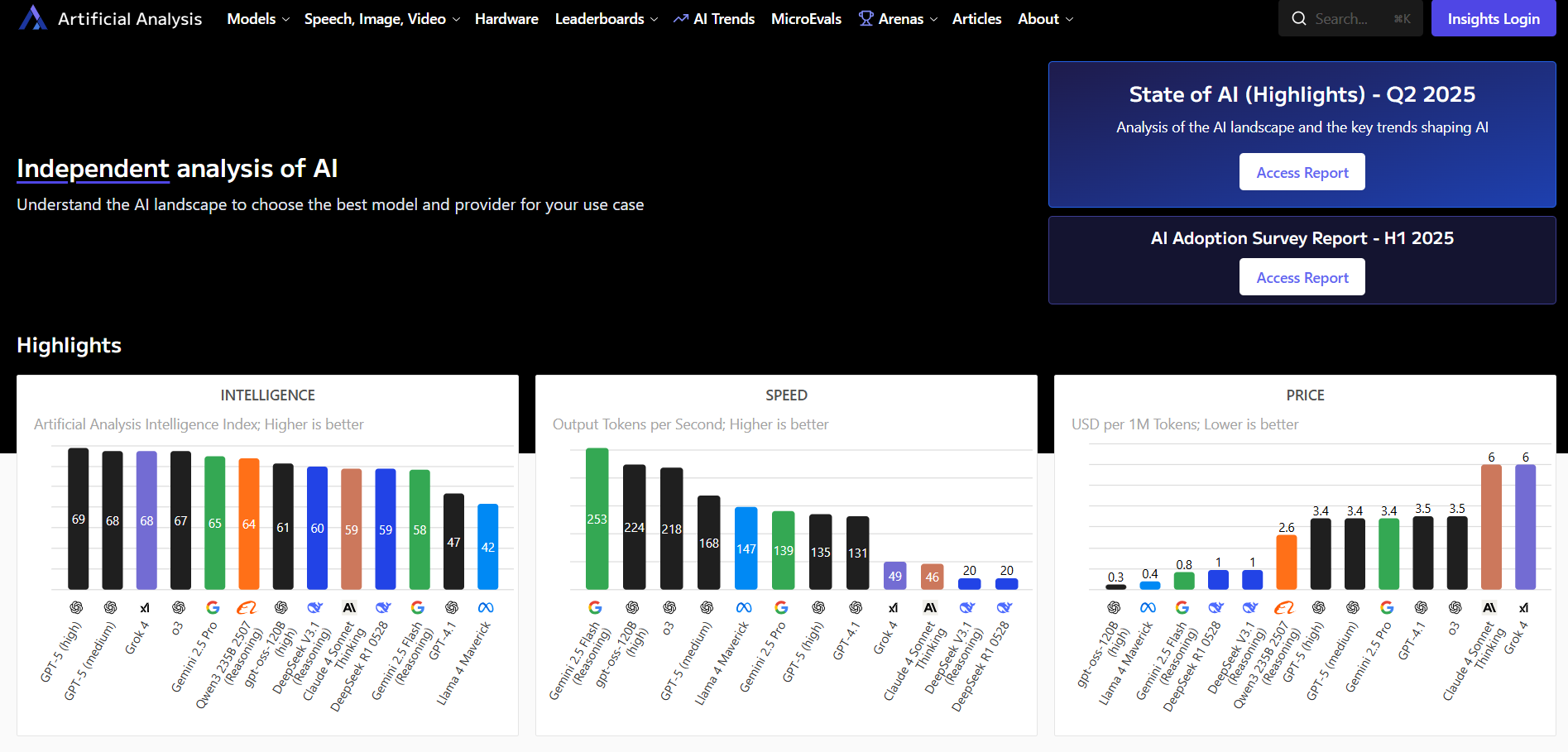
Purpose: Provides a clear business-centric overview of models' performance, costs, and speed.
Why it's helpful:
- Provides up-to-date comparisons of API & token pricing
- Essential to evaluate a model's performance-to-budget ratio
- Multiple benchmark tests against intelligence, speed, and price
- Helps with budget and performance planning for large-scale deployments
Why All Three Toolkits Are Important
Together, these three tools provide an all-encompassing, 360° view of models' intelligence, real-world usability, and operational efficiency. We'd recommend comparing and using all three to gauge how the models you're evaluating stack up.
Your 4-Step LLM Comparison Framework
To simplify things, here's a quick step-by-step framework to help you compare LLMs:
Step 1: Define Your Use Case
First, identify your use case. Depending on what you need the LLM to do, you'll need to select a suitable model. Without a clear use case, you risk overpaying for unneeded performance.
We'd recommend using a checklist to identify your requirements:
Checklist:
- Core Task – What do you need the AI to do most? Do you need help with coding, creative writing, summarization, a chatbot, etc?
- Specific models excel at specific tasks.
- Identify the most integral and start there before expanding LLM usage for other tasks.
- End-User – Who is the end-user of the model? Is it for developers, your marketing team, or analysts?
- Error Tolerance – How critical would a model's mistake be?
- A typo in an AI-generated marketing copy isn't a big problem, but an inaccurate financial report or "hallucinated" medical analysis can have serious consequences.
- Key Constraints – Factor in other key constraints such as budget, data privacy requirements, speed/latency, and integration needs.
Step 2: Determine Your Priorities
Using the above four pillars, rank them based on your use case. This is important to quantify which aspect you should prioritize.
Not every pillar is equally important, and depending on your specific use case, priorities will vary. We'd recommend using a simple scorecard. This makes it easy to quantify and evaluate trade-offs: areas where you're willing to compromise and integral areas:
Sample Scorecard Table:
| Pillar | Score (1–5) | Justification & Notes |
|---|---|---|
| Performance & Quality | 4 | Needs to generate compelling, brand-consistent copy that matches our tone. Occasional edits are accepted, but they should avoid off-brand messaging and harmful content. |
| Operational Metrics | 3 | Cost per token is important, as content generation can be high volume. However, speed/efficiency are secondary, not necessarily deal breakers. |
| Features & Usability | 5 | Must have strong integrations with existing marketing tools and systems (CMS, analytics, social schedulers), multimodal content support, and collaboration features. |
| Model Type & Ecosystem | 2 | Open-source is not a big factor. Other pillars are more valuable. |
Step 3: Gather the Evidence
Collect relevant, objective data from the toolkits based on your shortlist of models. Data is integral to the decision-making process and helps narrow down top candidates based on real-world performance.
We'd recommend building a simple spreadsheet to reference data from the toolkits:
Spreadsheet Template:
| LLM Name | Key Benchmark Score (1 – 10) | User Preference Score (1 – 10) | Cost / 1M Tokens | Speed (Tokens/s) (1 – 10) | Key Feature |
|---|---|---|---|---|---|
| GPT-4o | 8 | 8 | High Cost | 7 | Multimodal (text, vision, audio generation), strong reading capability; high cost |
| Claude 3.5 | 7 | 9 | Mid-Range | 6 | Large 200k context window, human-like responses, strong summarisation |
| Llama 3 | 5 | 6 | Budget Friendly | 8 | Open-source, customizable, flexible for fine-tuning, lowest cost of the three |
Pro-Tip: The goal of this step is to get a quick snapshot, not to run a full research project. Keep it simple.
Step 4: Conduct Real-World Tests
Your final decision should stem from hands-on testing. While benchmarks provide a general idea of an LLM's performance, they're not 100% infallible.
Testing with your specific use case in a "real-world" context gives you the best view of the model's capability and whether it meets your requirements.
We'd recommend creating a small test suite with 5-10 relevant prompts that reflect the actual use case. Test multiple models to evaluate performance and help make your decision.
Here are a few example test prompts based on different use cases:
- For a coding assistant: Feed in a tricky bug from your codebase.
- For marketing copy: Ask for an ad written in your brand's tone of voice.
- For summarization: Give it a long internal report and check the summary.
After the test prompt, create a scoring sheet to keep track and gauge the models' performance.
Scoring Sheet Example:
| Test Prompt | Model A Score (1–5) | Model B Score (1–5) | Notes |
|---|---|---|---|
| Bug Fix Suggestion | 5 | 3 | Model A provided runnable code with clear explanations that directly solved the issue |
| Creative Ad Copy | 4 | 5 | Model B captured the tone and style better, with more engaging and persuasive content |
| Report Summary | 3 | 4 | Model B's summary was succinct and to the point, easy to digest, and included clear action items |
LLM Comparison in Action Scenarios
Scenario 1: Sarah, the Marketing Manager, Building a Creative Copy Generator
The Goal: Brainstorm and generate ready-to-use creative, emotionally resonant ad copy for a new premium fashion line.
Framework in Action:
- Defined Use Case: Primarily creative writing and adherence to tone to align with the premium brand voice. The 'vibe' of the copy is more critical than accuracy.
- Priorities: Her scorecard clearly defines:
- Performance & Quality scoring 5/5
- While Operational Cost ranks 4/5
- Shows that while cost is important, quality of the ad copy is integral
- Evidence: Ignores academic benchmarks, focuses on LM Arena scores to shortlist models that users rank highly for creative writing tasks.
- Real World Test: Provides top 3 shortlisted models with a detailed brief on the new fashion line. Asks for 5 relevant taglines.
- One produces generic, boring copy.
- Another produces 'good enough' content, but isn't as engaging.
- Claude Sonnet 4 captures the brand's sophisticated branding and witty tone perfectly.
The Decision: Sarah chose Claude Sonnet 4 for delivering the best results for the specific creative job she requires, even at the higher cost to run and slightly lagging speed.
Scenario 2: Daniel, the CTO, Selecting a Coding Assistant for Engineers
The Goal: Looking to optimize the dev team's efficiency with a model that assists debugging and writing usable code.
Framework in Action:
- Defined Use Case: Requires high reasoning and accuracy performance, specifically in technical domains. Doesn't need to be adept at 'creative' tasks.
- Priorities: Daniel's scorecard values:
- Performance at 5/5 (reasoning, accuracy, problem-solving)
- Operational Metrics at 5/5 (speed, latency)
- Quality only scores 3/5 (stylistic polish less critical than correctness and efficiency)
- Evidence: Consulted the Hugging Face Leaderboard for coding benchmarks. Identified GPT-4o scored highest in code and general reasoning.
- Real World Test: Provided complex bugs from their internal codebase. GPT-4o consistently provided runnable, efficient fixes as well as suggested optimizations with:
- Cleaner functions
- Reduced redundancy
- Shortcuts for improved readability and performance
The Decision: Daniel selects GPT-4o for its balance in intelligence and speed for engineering workflows, even with a premium cost per token.
Scenario 3: Priya, the Data Privacy Officer at a Fintech Startup
The Goal: Financial compliance report summaries while ensuring strict regulatory standards.
Framework in Action:
- Defined Use Case: Accurate summarization with strict privacy and compliance requirements of utmost importance.
- Priorities: Her scorecard ranks:
- Model Type & Ecosystem at 5/5 (ensure LLM is open-source and can be kept in-house for data security)
- Performance & Quality ranks 4/5 (accurate summaries are important, but don't require perfection)
- Evidence: Consults Artificial Analysis & Hugging Face Leaderboards for cost-effective, customizable, open-source models. Identifies Llama 3 and Mistral as strong candidates, while also considering a premium closed option in Claude 3.5.
- Real World Test: Runs pilot tests summarizing quarterly financial reports.
- Claude 3.5 delivered polished summaries, but raised concerns over external data handling.
- Mistral outperformed Llama 3, integrating smoothly with compliance systems and enabling full data control.
The Decision: Priya chooses Mistral, prioritizing privacy, flexibility, and in-house control over marginal gains in fluency.
Conclusion
Choosing the right LLM doesn't have to be overwhelming. Our four-step framework, which uses four key pillars and a trusted LLM Comparison toolkit, empowers you to make a decision that's perfectly tailored to your needs. This process ensures you select the right model for your unique requirements, not just the most popular one.






Leave a Reply.