
- What Is an LLM Benchmark?
- The Role of Benchmarks in Choosing the Right LLM
- A Closer Look at Key LLM Benchmark Metrics
- A Practical Guide: How to Evaluate an LLM for Your Project
- What Happens After the Benchmarks
- Examples of LLM Benchmarks and What They Measure
- How to Read Benchmark Results
- GoInsight.ai: Turning Benchmarks into Workflows
Choosing the right Large Language Model (LLM) is a critical decision for businesses and developers. With dozens of powerful models like GPT-4, Claude, Gemini, and LLaMA now available, each with unique strengths, the key question is how to make an informed choice.
This is where LLM benchmarks come in, serving as a reliable and objective starting point for finding the best model for you.
What Is an LLM Benchmark?
An LLM benchmark is a standardized evaluation to test a large language model's performance on a set of tasks. Think of it as a controlled environment where multiple models take the same test with the same rules, allowing for a fair comparison of their effectiveness.
These tests rely on two key components:
- Benchmark Data: A specific dataset of prompts, problems, and questions used for the evaluation. All models use the same data to ensure a fair comparison.
- Scoring Rules: These determine how success is measured, whether by a specific 'correct' answer or through human evaluation.
Common Benchmark Types
Benchmarks can be categorized by the skills they test. Here are a few common types:
- Math & Logic: These are the "reasoning exams" for AI, testing a model's ability to solve problems like math word problems or logic puzzles.
- Language & Writing: These tests act as a "creative writing" test, assessing a model's fluency, grammar, and overall quality of generated text.
- Knowledge & Factuality: Think of these as a "general knowledge" quiz. They test whether a model provides accurate, factual answers and avoids "hallucinations"—false, but seemingly true information.
The Role of Benchmarks in Choosing the Right LLM
For businesses and developers, benchmarks are a critical tool for making informed decisions when selecting an LLM. They help you:
1. Filter Models: Instead of testing every available model, you can use benchmark results as an initial filter. This helps you narrow down your search to a few models that meet your minimum requirements, saving you time and resources.
2. Gauge Strengths & Weaknesses: Benchmarks are excellent at revealing a model’s profile. For example, a model might be a whiz at mathematical reasoning but struggle with fluent text generation. Understanding these trade-offs helps you find a model that perfectly matches your specific workflow.
3. Recognize Scores Aren’t Everything: While scores are important, they're not the final word. For a customer support chatbot, speed is crucial, but companies may prioritize a safer, more factual model, even if it scores lower in other areas. Similarly, a software team will value a model's coding benchmark scores over its writing accuracy. It's always about matching the model to the use case.
Ready to See the Results? Check out these LLM Leaderboards.
If you're eager to see how different LLMs stack up against each other, these leaderboards provide a direct look at the current rankings. Use them as a starting point for your research, and then come back to this guide to understand what those scores truly mean.
- Vellum AI's LLM Leaderboard: Designed for business use, Vellum's leaderboard focuses on real-world applications, providing a user-friendly comparison tool by blending public benchmarks with its own evaluations.
- Hugging Face Open LLM Leaderboard: And here's another direct link to the Hugging Face collection: This is a transparent, community-driven resource for ranking open-source LLMs. It relies on a suite of automated public benchmarks, making it a key tool for researchers.
A Closer Look at Key LLM Benchmark Metrics
LLM benchmarks use various metrics depending on what they measure. Here are some common ones, with a deeper explanation to help you understand what the numbers truly mean.
| Metric | What it Measures | Why it Matters for Businesses |
|---|---|---|
| Accuracy | The percentage of correct answers. | Shows a model's reliability for reasoning and factual tasks. |
| F1 Score | The balance between ‘precision’ and ‘recall’. | Ensures the output is both correct and complete. |
| BLEU / ROUGE | How similar the output is to human-written text. | Useful for text generation tasks like translation and summarization. |
| Pass@k | If at least one of the top k code outputs is correct. | Crucial for coding AIs, ensuring the generated code works as intended. |
| Truthfulness | The degree to which a model's output aligns with facts. | Critical for roles requiring fact-based output and customer-facing applications. |
| Safety/Toxicity | The ability to avoid offensive, harmful, or biased output. | Keeps the tool ‘safe’ and protects brand reputation. |
| Latency | Response time and speed. | Integral for real-time communication, like customer support chatbots. |
| Cost Efficiency | A model's performance versus its cost. | An important factor for large-scale deployment. |
Deeper Dive into Key Metrics: Accuracy, F1 Score & Pass@k
While the table above covers many key metrics, the following three are the most core and representative. Understanding them will help you master the fundamentals of LLM evaluation./p>
Accuracy
This is the most straightforward metric. If a model scores 85% on MMLU, it means it got 85% of the questions right. It’s a good starting point but can be misleading for tasks with multiple correct answers or for measuring nuances in language.
F1 Score
This is a more sophisticated metric that combines Precision and Recall.
- Precision measures how many of the model's answers are correct.
- Recall measures how many of the correct answers the model found.
- The F1 Score gives you a single value that represents both, which is perfect for tasks like summarization, where you need both accuracy and completeness.
Pass@k
This is critical for code generation. Instead of just giving one answer, a model might give you a few different options. Pass@1 means the first code block was correct, while Pass@10 means at least one of the top 10 code blocks was correct. A higher Pass@k score indicates a more reliable coding assistant.
A Practical Guide: How to Evaluate an LLM for Your Project
Moving beyond the general understanding, here is a step-by-step process for evaluating a model for a specific business or development project.
1. Define Your Use Case and Key Metrics
Before looking at any benchmarks, you must first define what success looks like for your specific application.
- Example: Building a Customer Service Chatbot: Your key metrics would be Truthfulness (the bot doesn't make things up), Latency (it responds quickly), and F1 Score (for summarization of customer issues).
- Example: Developing a Code Assistant: Your focus would be on Pass@k on coding benchmarks and Latency for a smooth user experience.
2. Select Relevant Benchmarks
Based on your defined metrics, select 3-5 benchmarks that are most relevant to your use case.
- For the Customer Service Chatbot, you would look at TruthfulQA and MT-Bench scores.
- For the Code Assistant, you would prioritize HumanEval and GSM8K.
3. Create Your Own Evaluation Set
This is where you bridge the gap between public benchmarks and your real-world application. Create a small, private dataset of prompts that are specific to your business and industry. This will test the model's performance on your actual data, which is far more indicative of real-world success.
4. Run Pilot Projects & A/B Testing
Use the models that scored well on the benchmarks (and your private dataset) in a small-scale pilot project. Run A/B tests to compare different models' real-world performance. This is the ultimate test of efficacy.
What Happens After the Benchmarks
While benchmarks are crucial for initial filtering, a real-world evaluation needs more.
Human-in-the-Loop Evaluation
For tasks with no single "correct" answer (e.g., creative writing, dialogue), a human evaluator is essential. A human can assess nuances like tone, style, and brand voice that automated metrics can’t.
Adversarial Testing (Red Teaming)
This involves intentionally trying to make the model fail. You can create adversarial inputs to test for:
- Jailbreaks: Prompts designed to bypass safety filters.
- Toxicity: Prompts that try to elicit offensive or biased responses.
- Edge Cases: Unexpected or ambiguous prompts that might confuse the model.
Continuous Monitoring
Evaluation is not a one-time event. You should continuously monitor your chosen model in production to track performance, especially as the model is updated or the prompts and data change.
Examples of LLM Benchmarks and What They Measure
Here is a quick overview of some widely used LLM benchmarks and what they’re used for to give you a better idea of the evaluation process:
| Benchmark Name | Task Type | Purpose | Typical Metric | Best Use Case | Notes / Limitations |
|---|---|---|---|---|---|
| MMLU (Massive Multitask Language Understanding) | Reasoning and Knowledge | Tests general knowledge across 57 subjects with over 15,000 multiple-choice questions. | Accuracy | Checking broad model intelligence | Susceptible to ‘data contamination’. |
| BIG-bench | Mixed tasks (language, puzzles) | Evaluates creative, logical, and common-sense abilities across 200+ tasks. | Accuracy / Human Evaluation | Research & general performance | The variety of tasks can lead to inconsistent results and subjective scores due to human evaluation. |
| HELM (Holistic Evaluation of Language Models) | Multi-metric analysis | Evaluates accuracy, robustness, fairness, toxicity, and efficiency. | Composite metrics | Balanced model assessment | Harder to interpret for businesses, as it takes many factors into account. |
| ARC (AI2 Reasoning Challenge) | Reasoning & common sense | Tests over 7,000 science questions that require logic and advanced question-answering. | Accuracy | Measuring reasoning skills without human intervention | Limited scope for real-world applications as it focuses on multiple-choice science questions. |
| TruthfulQA | Factuality & truthfulness | Verifies that output answers are true and informative, avoiding "hallucinations". | Truthfulness score based on max similarity to true/false answers | Research & customer-facing bots that need to be factual and trustworthy | Does not measure the depth of the explanation. |
| GSM8K | Multi-step mathematical reasoning | Uses 8,500 grade-school math word problems. | Accuracy | Applications requiring reasoning-heavy components, especially with math | Limited to math word problems; doesn't test higher-level scientific reasoning. |
| HumanEval | Code generation | Evaluates a model’s ability to generate usable, working code. | Pass@k | Programming assistants for software teams | Limited dataset size can make models appear better than they are. |
| MT-Bench | Dialogue | Tests a model’s conversational capabilities with multi-turn interactions. | Human evaluation | Support AI and customer-facing chatbots | Relies on human raters, which can lead to subjective results. |
Based on the table, you can see a few clear patterns in how these benchmarks operate:
- Coding Benchmarks like HumanEval use the Pass@k metric to ensure the generated code actually works.
- Reasoning Benchmarks like GSM8K focus on Accuracy, as logical problems usually have one correct answer.
- Factuality Benchmarks like TruthfulQA prioritize Truthfulness and Safety to catch models that generate false but convincing information.
- Language Generation Benchmarks like MT-Bench use scores like BLEU/ROUGE and human evaluation to measure quality, which is more important than simple accuracy for these tasks.
How to Read Benchmark Results
Understanding benchmark results can seem complex, filled with confusing graphs and unfamiliar acronyms. Here is a general guide to help you interpret them effectively:
1. Understand the Benchmark’s Focus
Not all benchmarks measure the same thing, so first, understand what a specific test is designed to measure. For example, a model's poor score on HumanEval (used for coding) doesn't mean it’s not a capable chatbot. Focus only on the benchmarks relevant to your use case.
2. Consider More Than One Score
Basing your decision on a single score can be misleading. A model might score 90% in reasoning but only 60% in overall safety. To get a complete picture, use multiple benchmarks (3-5) to understand its full profile of strengths and weaknesses.
3. Match Benchmark Evaluations to Your Use Case
Every application has different priorities. For example:
- Coding teams should look at HumanEval (Pass@k) and latency scores for efficient performance.
- Customer support chatbots need high scores on TruthfulQA and MT-Bench for a natural, factual conversation.
- Research assistants should excel on MMLU, BIG Bench, and TruthfulQA to ensure both a wide knowledge base and factual correctness.
4. Test Models in the Real World
While benchmarks provide a foundation, real-world performance is the ultimate test. Deploy pilot projects to measure a model's output in your specific workflow. Track real-world metrics like user satisfaction, error rates, and cost per request to get a full view of its efficacy.
GoInsight.ai: Turning Benchmarks into Workflows
You've learned what LLM benchmarks are and how to use them to vet models for your specific needs. The next logical step is applying this knowledge to build a powerful AI application. This is where GoInsight.ai comes in.
GoInsight.ai is a powerful AI-powered workflow platform that allows you to integrate LLMs into your custom business processes seamlessly.
This platform provides a range of pre-integrated LLM nodes. You can browse and select the best model for your specific task, directly applying the insights you’ve gained from benchmarks.
How it works:
1. Select Your Node: You can select a specific LLM node from our library of integrated models. Your knowledge of benchmarks will guide this choice. For example, if you're building a legal research tool, you would select a model that scores highly on 'TruthfulQA' to ensure factual accuracy. If you're creating a programming assistant, you'll choose a model that has a 'high Pass@k score' on 'HumanEval.'
2. Build Your Workflow: Drag and drop the selected LLM node into a workflow canvas. Connect it with other nodes for data ingestion, processing, or final output.
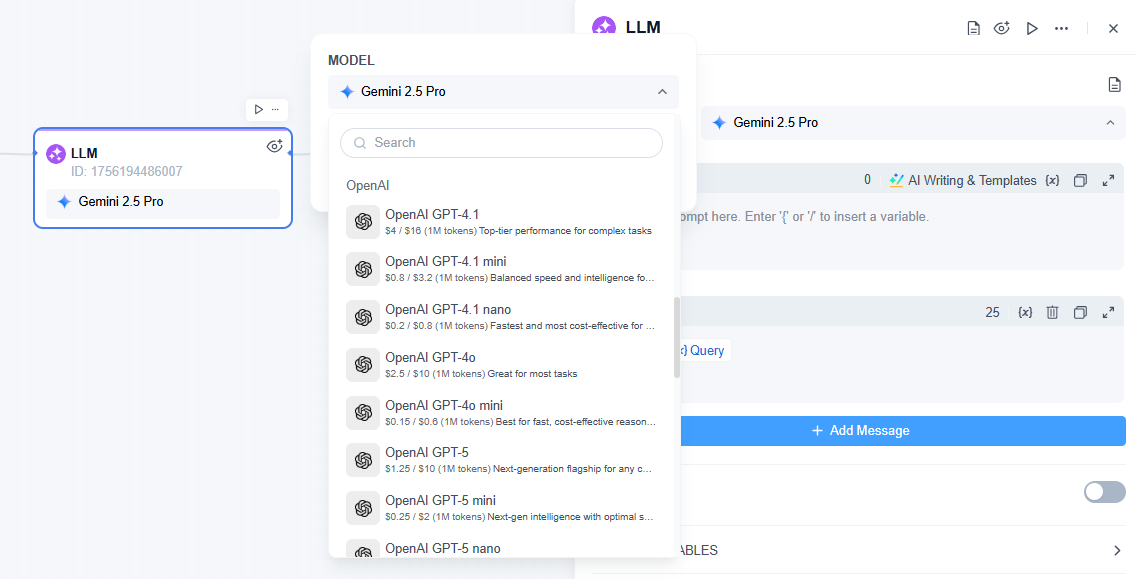
3. Test and Deploy: Run your custom evaluation sets directly within GoInsight.ai, then A/B test different models in a controlled environment to see real-world performance before full-scale deployment.
Conclusion
LLM benchmarking might seem daunting, but it's a necessary process to find the optimal model for your needs. With this guide, we hope the process feels a little easier to comprehend.
Remember that a leaderboard position on its own isn’t the be-all and end-all of an LLM. By testing a model against your specific needs, you'll be able to confidently choose the right tool for the job.





Leave a Reply.